
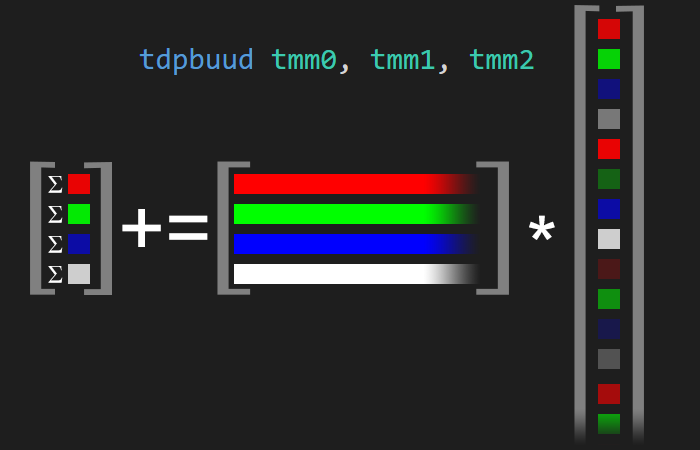
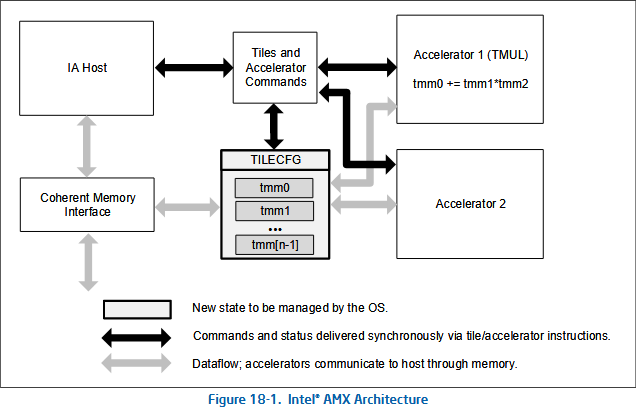
To go beyond vectors, Intel introduced Advanced Matrix eXtensions into their Sapphire Rapids processors, allowing massive matrix-operation instructions into the ISA. Apple also implemented a similar instruction set extension.1

The shape of these matrices are configured by a ldtilecfg-instruction that refers to a 64-byte structure in memory defining the AMX register-state. The 64-byte tile-configration structure is pretty optimistic, allowing a total of 16 tiles to be configured and with 14 reserved bytes for future configuration data.
struct tileconfig_t
{
uint8_t palette_id; // Currently only supports "1"
uint8_t startRow; // Intended for interrupted operations, leave this 0
uint8_t reserved[14];
uint16_t colb[16]; // bytes per row for tile-[0,15]
uint8_t rows[16]; // number of rows for tile-[0,15]
};
The currently loaded tile-configuration can also be written back to memory with a
sttilecfg-instruction,
which is typically done when a memory-fault has occured and you want to
figure out which row the memory-fault occured at. It will assign the
startRow value to the next row-index after the row where a memory fault has
occured to allow an opportunity for the instruction stream to fix the issue
and restart the operation.
AMX currently only implements a palette_id of 1 which designates the
AMX-state as eight massive 1KiB tile-registers(tmm0-tmm7).
Each of the eight tiles represents a two-dimensional matrix(a rank-2 tensor to
be technical) for a total of 8KiB of total register-space for different
accelerators to operate upon:
Intel® 64 and IA-32 Architectures Software Developer’s Manual Vol. 1 (December 2022)
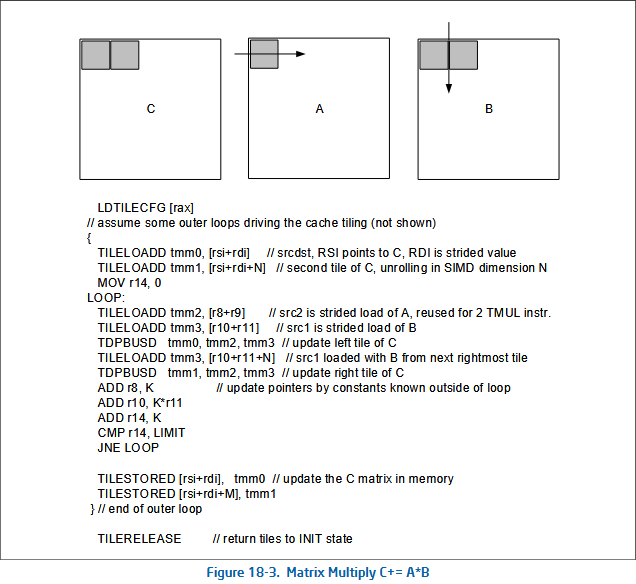
Tile-data can be loaded and stored by utilizing the
tileloadd/tilestored-instructions
to address subsequent rows of matrix-data separated by stride bytes to or from
the designated tile-register by its index.
tileloaddt1 will load data and bypass storing it into the the processor’s cache, allowing your cache to be better-utilized for other things. This additional cache-hinting helps avoid beating up your processor’s caches with possibly hundreds or thousands of of one-off 1KiB reads that aren’t worth holding onto in cache. This is good in cases when you are reading some data once and already know that you won’t be touching it again for a while.
When you are done with your AMX workload,
tilerelease
must be called to release the AMX-state back into its initial disabled state.
Similar to vzeroupper,
tilerelease in an instruction-stream signals that the tiles will not be utilized
any more and can reset any state associated with AMX such as by returning
resources back to the
register-file, adjusting clock
speeds, power limits, etc.
The operating system may also now be able to opt-out of having to preserve over
8KiB of AMX’s additional thread-state in the case that a context-switch was to
occur in the middle of your AMX workload.
A typical AMX workload is characterized by a ldtilecfg, some tileloaddd to
load some data into the tiles, some tile-arithmetic itself such as tdpbusd,
storing the results somewhere with a tilestored, and an outro call to
tilerelease:
Intel® 64 and IA-32 Architectures Software Developer’s Manual Vol. 1 (December 2022)
With C or C++ intrinsics provided by immintrin.h this looks something like:
#include <immintrin.h>
...
// Configure tiles
tileconfig_t tileconfig = {};
tileconfig.palette_id = 1;
tileconfig.startRow = 0;
// Tile 0
tileconfig.rows[0] = 16; // 16 rows
tileconfig.colb[0] = 64; // each row is 64-bytes (16 ints)
// 16x16 matrix of int32s
// Tile 1
tileconfig.rows[1] = 4; // 4 rows
tileconfig.colb[1] = 16; // each row is 16-bytes (4 ints)
// 4x4 matrix of int32s
// Tile 2
tileconfig.rows[2] = 16; // 16 rows
tileconfig.colb[2] = 4; // each row is 4-bytes (1 int)
// 16x1 matrix of int32s
_tile_loadconfig((const void*)&tileconfig);
// ...
// Start using tiles 0,1,2
// ...
_tile_loadd(0, blah_src, 64);
_tile_loadd(1, blah_src, 64);
_tile_loadd(2, blah_src, 64);
// ...
_tile_dpbuud(2, 0, 1);
// ...
_tile_stored(2, blah_dst, 64);
// ...
// Release all allocated tiles when you are done
// Think of this like `vzeroupper`
_tile_release();
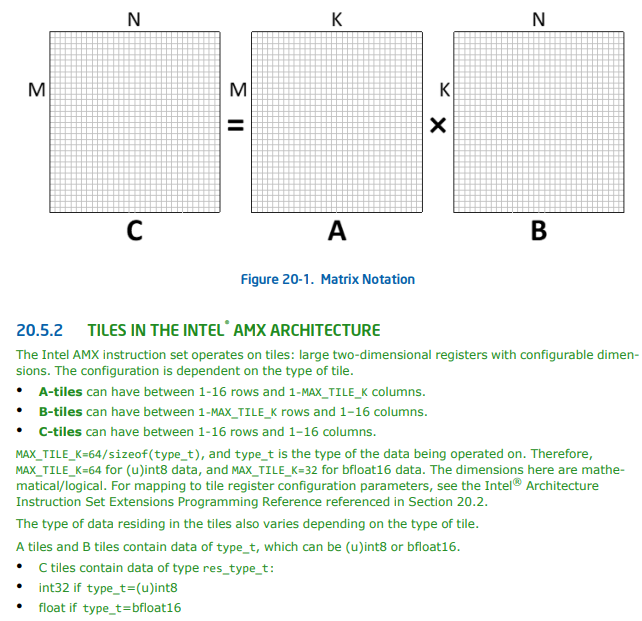
Probably the most confusing part of all this is that the shape of a matrix is defined as a count of rows and a byte-size of columns. So you will need to orient your matrix-size around the particular instructions and data-types that you intend to use.
All of the current AMX instruction extensions use 32-bit integers as their destination type so the column size will likely need to be a multiple of 4.
Intel® 64 and IA-32 Architectures Optimization Reference Manual (January 2023)
__tile1024i
You can utilize the __tile1024i-type to allow the compiler to handle
configuring tiles, allocating registers, register-spilling, and loading/storing
configured tiles for you.
This type is RAII-based and gets rid of much of the head-ache of trying to
handle register-allocation and tile configurations yourself.
Intel’s intrinsic guide documents this type as well.
Currenty(Wed Jan 18 12:27:19 AM PST 2023) this type is supported in clang 15.0.7.
#include <immintrin.h>
...
// Configure tiles
// tileconfig_t tileconfig = {};
// tileconfig.palette_id = 1;
// tileconfig.rows[0] = 16; // 16 rows
// tileconfig.colb[0] = 64; // each row is 64-bytes (16 ints)
__tile1024i TileA = {16, 64}; // 16x16 matrix of int32s
// tileconfig.rows[1] = 4; // 4 rows
// tileconfig.colb[1] = 16; // each row is 16-bytes (4 ints)
__tile1024i TileB = {4, 16}; // 4x4 matrix of int32s
// tileconfig.rows[2] = 16; // 16 rows
// tileconfig.colb[2] = 4; // each row is 4-bytes (1 int)
__tile1024i TileC = {16, 4}; // 16x1 matrix of int32s
// The compiler will automatically handle register allocations
// and tile-configurations
// _tile_loadconfig((const void*)&tileconfig);
// Start using tiles
// ...
__tile_loadd(TileA, blah_src, 64); // _tile_loadd(0, blah_src, 64);
__tile_loadd(TileB, blah_src, 64); // _tile_loadd(1, blah_src, 64);
__tile_loadd(TileC, blah_src, 64); // _tile_loadd(2, blah_src, 64);
// ...
__tile_dpbuud(TileC, TileA, TileB); // _tile_dpbuud(2, 0, 1);
// ...
__tile_stored(blah_dst, 64, TileC); // _tile_stored(2, blah_dst, 64);
// ...
// The compiler will automatically call tilerelease once your
// AMX workload goes out of scope
// _tile_release();
This isn’t about Machine Learning or Artificial Intelligence
I don’t care so much about artificial intelligence and machine learning workloads, but these new instructions have some pretty useful non-AI/ML workload uses. “Deep Learning Boost™️” usually just means they added some new dot-product or multiply-accumulate instructions. Dot-products and multiply-accumulates can be pretty easily “tricked” into doing masking, horizontal-sums, and even bit-arithmetic.
Intel® 64 and IA-32 Architectures Software Developer’s Manual Vol. 1 (December 2022)
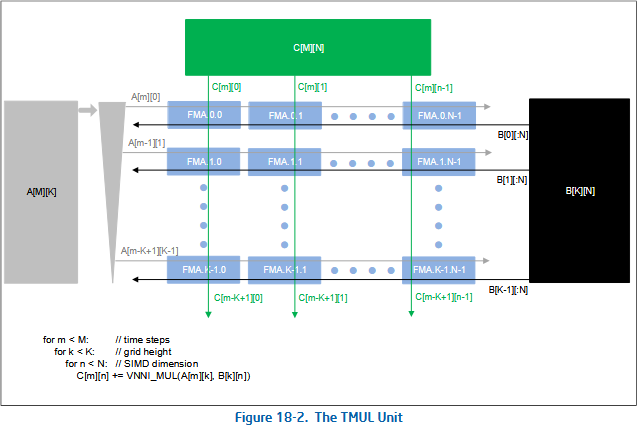
The baseline AMX instruction set only defines a few tile-maintenance instructions and does not define any actual arithmetic just yet.
Similar to AVX-512, a foundational AMX instruction-set is extended upon with additional instruction sets that adds support for INT8, BF16, and FP16 data-type operations.
More importantly, thanks to Machine Learning or Artificial Intelligence, INT8 arithmetic is suddenly cool again!
AMX-INT8
AMX-INT8 introduces four additional instructions to the baseline AMX instruction set.
| Instruction | Description |
|---|---|
tdpbssd |
tile dot-product bytes: multiply signed to signed bytes and accumulate to a dword(32-bit integer) |
tdpbsud |
tile dot-product bytes: multiply signed to unsigned bytes and accumulate to a dword(32-bit integer) |
tdpbusd |
tile dot-product bytes: multiply unsigned to signed bytes and accumulate to a dword(32-bit integer) |
tdpbuud |
tile dot-product bytes: multiply unsigned to unsigned bytes and accumulate to a dword(32-bit integer) |
Intel® 64 and IA-32 Architectures Optimization Reference Manual (January 2023)
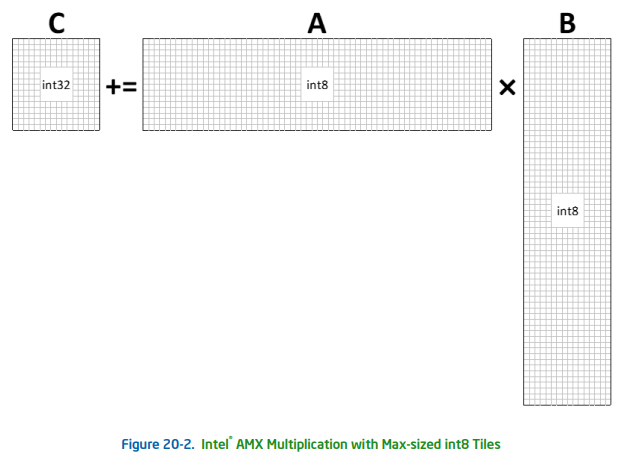
With these wide INT8 dot-products, a 1xN-vector of all 0x01 bytes can be
multiplied with another Nx1-vector of bytes to implement a large sum-of-bytes
operation2:
[byte]
[byte]
[byte]
[Sum] = [0x1, 0x1, 0x1, 0x1, 0x1, ...] * [byte]
[byte]
[byte]
[....]
If the byte-vector was some kind of structured data, such as the Red, Green, Blue, and Alpha bytes of an image, then these individual channels can be masked out into individual sums
[Red ]
[Green]
[Sum-Red ] [0x1, 0x0, 0x0, 0x0, ...] [Blue ]
[Sum-Green] = [0x0, 0x1, 0x0, 0x0, ...] * [Alpha]
[Sum-Blue ] [0x0, 0x0, 0x1, 0x0, ...] [Red ]
[Sum-Alpha] [0x0, 0x0, 0x0, 0x1, ...] [Green]
[Alpha]
[Red ]
[Green]
[.... ]
By dividing these individual channel-sums by the number of pixels in the image, then this becomes a very fast way to derive the average color of an image!
Typically with vector-instructions like AVX or AVX512, one would need four separate dot-product operations to mask and sum lanes of color channels and would require byte-shuffling of some kind to ensure data is in the right lanes.3 With AMX, all this arithmetic is done with one instruction!
The star of the show here is the tdpbuud instruction.
Synopsis
void __tile_dpbuud (__tile1024i* dst, __tile1024i src0, __tile1024i src1) #include <immintrin.h> Instruction: tdpbuud tmm, tmm, tmm CPUID Flags: AMX-INT8Description
Compute dot-product of bytes in tiles with a source/destination accumulator. Multiply groups of 4 adjacent pairs of unsigned 8-bit integers in src0 with corresponding unsigned 8-bit integers in src1, producing 4 intermediate 32-bit results. Sum these 4 results with the corresponding 32-bit integer in dst, and store the 32-bit result back to tile dst. The shape of tile is specified in the struct of __tile1024i. The register of the tile is allocated by compiler.
Operation
DEFINE DPBD(c, x, y) { tmp1 := ZeroExtend32(x.byte[0]) * ZeroExtend32(y.byte[0]) tmp2 := ZeroExtend32(x.byte[1]) * ZeroExtend32(y.byte[1]) tmp3 := ZeroExtend32(x.byte[2]) * ZeroExtend32(y.byte[2]) tmp4 := ZeroExtend32(x.byte[3]) * ZeroExtend32(y.byte[3]) RETURN c + tmp1 + tmp2 + tmp3 + tmp4 } FOR m := 0 TO dst.rows - 1 tmp := dst.row[m] FOR k := 0 TO (src0.colsb / 4) - 1 FOR n := 0 TO (dst.colsb / 4) - 1 tmp.dword[n] := DPBD(tmp.dword[n], src0.row[m].dword[k], src1.row[k].dword[n]) ENDFOR ENDFOR write_row_and_zero(dst, m, tmp, dst.colsb) ENDFOR zero_upper_rows(dst, dst.rows) zero_tileconfig_start()
In a single 8-bit dot-product operation:
A four-row matrix of specially-placed 0x01 and 0x00 byte-values is
multiplied to mask out the individual channels out of the incoming RGBA
matrix-values.
After the multiplication isolates the color channels, the masked values are
added together intto a 32-bit value and are then accumulated into a 32-bit sum.
Here is some sample code to illustrate utilizing this instruction:
#include <array>
#include <cstddef>
#include <cstdint>
#include <cstdio>
#include <immintrin.h>
int main()
{
// {number of rows, column size in bytes}
__tile1024i PixelTile = {16, 4}; // 16rowsx4b (16x1) 16 pixels (16 ints)
__tile1024i MaskTile = {4, 64}; // 4rowx16b (4x16) masks (4 x 16 ints)
__tile1024i SumTile = {4, 4}; // 4rowsx4b (4x1) four RGBA sums (4 ints)
// [R Sum32] [RRRRRRRR...] [ RGBA ]
// [G Sum32] += [GGGGGGGG...] * [ RGBA ]
// [B Sum32] [BBBBBBBB...] [ RGBA ]
// [A Sum32] [AAAAAAAA...] [ RGBA ]
// Sums Masks [ RGBA ]
// [ ... ]
// Pixels
// Generate Mask-Matrix
std::array<std::uint32_t, 4 * 16> MaskData;
for( std::size_t ChannelIndex = 0; ChannelIndex < 4; ++ChannelIndex )
{
for( std::size_t j = 0; j < 16; ++j )
{
// Each row is masking a particular RGBA channel.
// 0: 0x00'00'00'01
// 1: 0x00'00'01'00
// 2: 0x00'01'00'00
// 3: 0x01'00'00'00
MaskData[j + ChannelIndex * 16]
= (uint32_t(1) << (ChannelIndex * 8));
}
}
// Load mask-matrix
// Each row is composed of 16x32-bit integers. 64 bytes per row
__tile_loadd(&MaskTile, MaskData.data(), sizeof(std::uint32_t) * 16);
// Initialize the Sum to 0, 0, 0, 0
__tile_zero(&SumTile);
// Generate a sample RGBA "image" of all the same pixels
std::array<std::uint32_t, 16 * 100000> PixelData;
PixelData.fill(0xAA'BB'CC'DD); // Fill it with some pixel data
// Process 16 pixels at a time
for( std::size_t i = 0; i < PixelData.size(); i += 16 )
{
// Load 64 bytes of RGBA pixel data, 16 pixels
// Be careful here, each "row" is 4 bytes long, so the stride is 4 bytes
__tile_stream_loadd(&PixelTile, PixelData.data() + i, 4);
// 8-bit dot-product rows of A and columns of B into matrix C of 32-bit
// sums
__tile_dpbuud(&SumTile, MaskTile, PixelTile);
}
// Store vector of sums
std::array<std::uint32_t, 4> SumData;
__tile_stored(SumData.data(), 4, SumTile);
// Print
for( std::size_t i = 0; i < 4; ++i )
{
std::printf("%08X ", SumData[i] / std::uint32_t(PixelData.size()));
}
// 000000DD 000000CC 000000BB 000000AA
}
I generated an “image” with 0xAA'BB'CC'DD-pixels(note the
bytes will be stored as 0xDD, 0xCC, 0xBB, 0xAA in memory) and utilized the
__tile_stream_loadd intrinsic to map to the tileloaddt1 instruction so that
it does not try to keep the pixel data around in the cache.
Since the sums are 32-bit values, summing more than 0xFFFFFFFF/0xFF=16843009
pixels will make this code susceptible to overflow issues.
I did not add code to handle this, but if you want to safely handle this then an
outer-loop will be necessary where after processing 16843009 pixels, the
32-bit sum in the inner-loop must be added to an outer 64-bit sum, which would
allow the code to be overflow-safe for up to
0xFFFFFFFFFFFFFFFF/0xFF=72340172838076673 pixels.
Click here to expand the assembly output
.LCPI0_0:
.long 1 # 0x1
.LCPI0_1:
.long 256 # 0x100
.LCPI0_2:
.long 65536 # 0x10000
.LCPI0_3:
.long 16777216 # 0x1000000
.LCPI0_4:
.long 2864434397 # 0xaabbccdd
main: # @main
push rbx
sub rsp, 6400336
vxorps xmm0, xmm0, xmm0
vmovups zmmword ptr [rsp + 16], zmm0
mov byte ptr [rsp + 16], 1
mov byte ptr [rsp + 64], 4
mov word ptr [rsp + 32], 4
mov byte ptr [rsp + 65], 4
mov word ptr [rsp + 34], 64
mov byte ptr [rsp + 66], 16
mov word ptr [rsp + 36], 4
ldtilecfg [rsp + 16]
vbroadcastss ymm0, dword ptr [rip + .LCPI0_0] # ymm0 = [1,1,1,1,1,1,1,1]
vmovups ymmword ptr [rsp + 80], ymm0
vmovups ymmword ptr [rsp + 112], ymm0
vbroadcastss ymm0, dword ptr [rip + .LCPI0_1] # ymm0 = [256,256,256,256,256,256,256,256]
vmovups ymmword ptr [rsp + 144], ymm0
vmovups ymmword ptr [rsp + 176], ymm0
vbroadcastss ymm0, dword ptr [rip + .LCPI0_2] # ymm0 = [65536,65536,65536,65536,65536,65536,65536,65536]
vmovups ymmword ptr [rsp + 208], ymm0
vmovups ymmword ptr [rsp + 240], ymm0
vbroadcastss ymm0, dword ptr [rip + .LCPI0_3] # ymm0 = [16777216,16777216,16777216,16777216,16777216,16777216,16777216,16777216]
vmovups ymmword ptr [rsp + 272], ymm0
vmovups ymmword ptr [rsp + 304], ymm0
mov eax, 64
lea rcx, [rsp + 80]
mov dx, 64
mov si, 4
tileloadd tmm1, [rcx + rax]
tilezero tmm0
mov eax, 248
vbroadcastss ymm0, dword ptr [rip + .LCPI0_4] # ymm0 = [2864434397,2864434397,2864434397,2864434397,2864434397,2864434397,2864434397,2864434397]
.LBB0_1: # =>This Inner Loop Header: Depth=1
vmovups ymmword ptr [rsp + 4*rax - 656], ymm0
vmovups ymmword ptr [rsp + 4*rax - 624], ymm0
vmovups ymmword ptr [rsp + 4*rax - 592], ymm0
vmovups ymmword ptr [rsp + 4*rax - 560], ymm0
vmovups ymmword ptr [rsp + 4*rax - 528], ymm0
vmovups ymmword ptr [rsp + 4*rax - 496], ymm0
vmovups ymmword ptr [rsp + 4*rax - 464], ymm0
vmovups ymmword ptr [rsp + 4*rax - 432], ymm0
vmovups ymmword ptr [rsp + 4*rax - 400], ymm0
vmovups ymmword ptr [rsp + 4*rax - 368], ymm0
vmovups ymmword ptr [rsp + 4*rax - 336], ymm0
vmovups ymmword ptr [rsp + 4*rax - 304], ymm0
vmovups ymmword ptr [rsp + 4*rax - 272], ymm0
vmovups ymmword ptr [rsp + 4*rax - 240], ymm0
vmovups ymmword ptr [rsp + 4*rax - 208], ymm0
vmovups ymmword ptr [rsp + 4*rax - 176], ymm0
vmovups ymmword ptr [rsp + 4*rax - 144], ymm0
vmovups ymmword ptr [rsp + 4*rax - 112], ymm0
vmovups ymmword ptr [rsp + 4*rax - 80], ymm0
vmovups ymmword ptr [rsp + 4*rax - 48], ymm0
vmovups ymmword ptr [rsp + 4*rax - 16], ymm0
vmovups ymmword ptr [rsp + 4*rax + 16], ymm0
vmovups ymmword ptr [rsp + 4*rax + 48], ymm0
vmovups ymmword ptr [rsp + 4*rax + 80], ymm0
vmovups ymmword ptr [rsp + 4*rax + 112], ymm0
vmovups ymmword ptr [rsp + 4*rax + 144], ymm0
vmovups ymmword ptr [rsp + 4*rax + 176], ymm0
vmovups ymmword ptr [rsp + 4*rax + 208], ymm0
vmovups ymmword ptr [rsp + 4*rax + 240], ymm0
vmovups ymmword ptr [rsp + 4*rax + 272], ymm0
vmovups ymmword ptr [rsp + 4*rax + 304], ymm0
vmovups ymmword ptr [rsp + 4*rax + 336], ymm0
add rax, 256
cmp rax, 1600248
jne .LBB0_1
mov rax, -80
lea rcx, [rsp + 336]
mov r8d, 4
mov si, 4
mov di, 16
mov bx, 64
.LBB0_3: # =>This Inner Loop Header: Depth=1
tileloaddt1 tmm2, [rcx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 64]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 128]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 192]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 256]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
add rax, 80
add rcx, 320
cmp rax, 1599920
jb .LBB0_3
mov eax, 4
mov rcx, rsp
mov dx, 4
tilestored [rcx + rax], tmm0
mov eax, dword ptr [rsp]
shr eax, 9
imul rsi, rax, 10995117
shr rsi, 35
lea rbx, [rip + .L.str]
mov rdi, rbx
xor eax, eax
vzeroupper
call printf@PLT
mov eax, dword ptr [rsp + 4]
shr eax, 9
imul rsi, rax, 10995117
shr rsi, 35
mov rdi, rbx
xor eax, eax
call printf@PLT
mov eax, dword ptr [rsp + 8]
shr eax, 9
imul rsi, rax, 10995117
shr rsi, 35
mov rdi, rbx
xor eax, eax
call printf@PLT
mov eax, dword ptr [rsp + 12]
shr eax, 9
imul rsi, rax, 10995117
shr rsi, 35
mov rdi, rbx
xor eax, eax
call printf@PLT
xor eax, eax
add rsp, 6400336
pop rbx
tilerelease
ret
.L.str:
.asciz "%08X "
Clang has gone the extra step to unroll
the main iteration loop!
The generated assembly processes 5 tiles per iteration with each tdpbuud
processing 16 pixels each.
That’s 80 pixels processed per iteration!
...
.LBB0_3: # =>This Inner Loop Header: Depth=1
tileloaddt1 tmm2, [rcx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 64]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 128]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 192]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
lea rdx, [rcx + 256]
tileloaddt1 tmm2, [rdx + r8]
tdpbuud tmm0, tmm1, tmm2
add rax, 80
add rcx, 320
cmp rax, 1599920
jb .LBB0_3
...
A Sapphire Rapids processor is not available to pedestrians like me yet, but the
Intel Software Development Emulator
can be used to verify the implementation by simulating a Sapphire Rapids
processor with the -spr flag.
% clang AMX-AvgColor.cpp -O2 -march=sapphirerapids
% sde64 -spr -- ./a.out
000000DD 000000CC 000000BB 000000AA
I have no immediate way of getting the detailed performance benchmarks of this running on actual hardware though unless someone allows me remote access to their data-center running a Sapphire Rapid Xeon(very unlikely). Until then, Intel released some performance characteristics for the new AMX instructions in their latest optimization reference manual.
Intel® 64 and IA-32 Architectures Optimization Reference Manual (January 2023)
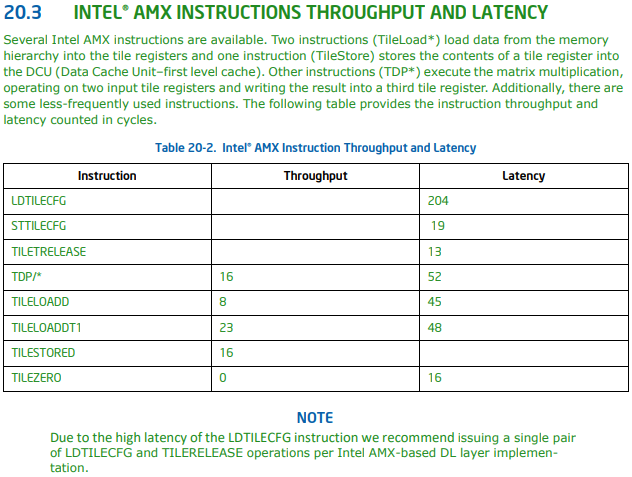
All tdp* instructions seem to have a throughput of 16 cycles and a latency of
52 cycles, tileloaddt1 has a throughput of 23 cycles and a latency of 48 cycles.
Moving around such a large amount of memory isn’t cheap, and is probably why
clang decided to unroll the loop to try and hide the memory-latency.
I don’t know any of the exact port-utilizations for these instructions, though the Intel Architecture Day 2021 press-kit presentation has this marketing graphic that seems to imply that all AMX instructions execute on Port 05, and resides right next to all the other vector units.

A lot of this is speculative. Without any actual hardware it’s hard to say if this is actually a viable implementation. Though, I’d imagine that this would still be faster than the alternative SSE, AVX, and AVX512 instruction-streams that I’ve come up with.3
Until then, I’ll put this silly usage of AMX instructions out there.
