
GL_NV_shader_sm_builtins is no longer in the Nvidia beta-driver-jail, and can allow shaders to access the index of the physical Streaming multi-processor and warp that a particular compute kernel dispatch is executing upon.
My laptop has a Nidia GTX 1650 Max-Q which features the TU117 Turing-architecture chip.
Image from anandtech.com
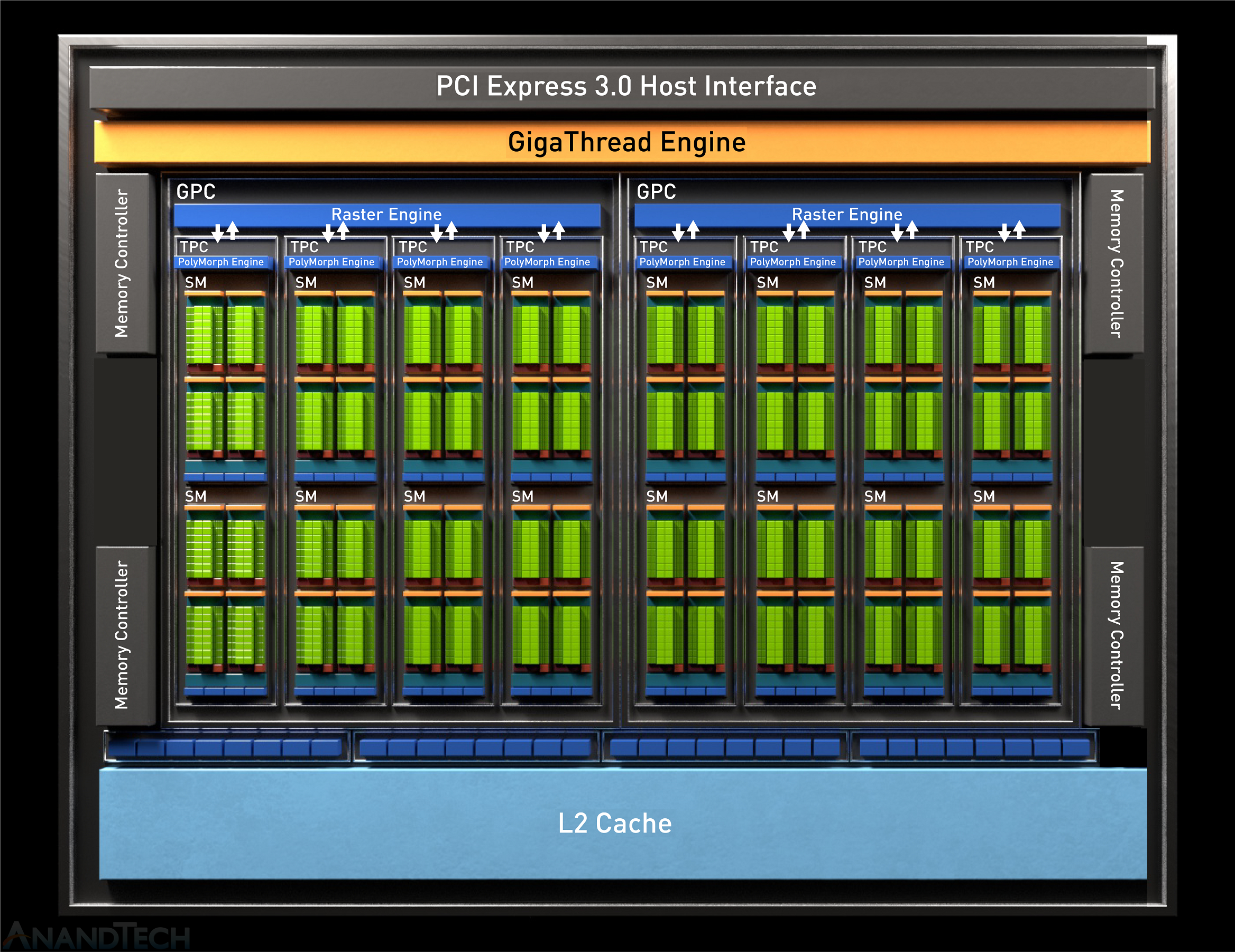
Here’s a deeper dive into the Turing Streaming-Multiprocessors
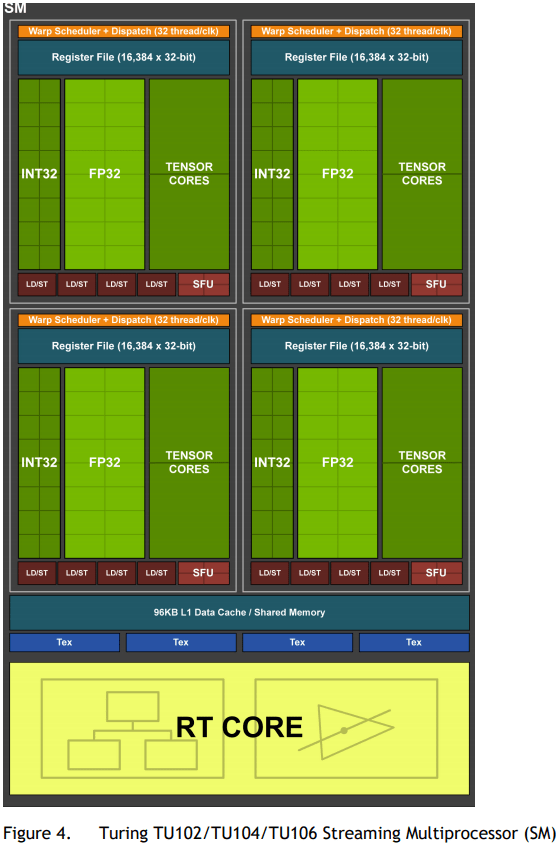
The GTX 1650 is a special-case implementation of the Turing architecture that does not implement the “True Turing” video encoding engine or any of the new Tensor Cores or Ray Tracing Cores, but the SM is generally the same, save for the absense of the die-space that these non-essential features would have taken up.
…each SM has a total of 64 FP32 Cores and 64 INT32 Cores…
The Turing SM is partitioned into four processing blocks, each with 16 FP32 Cores, 16 INT32 Cores, two Tensor Cores, one warp scheduler, and one dispatch unit.
So what’s a warp?
A warp is what Nvidia uses to describe a bundle of 32 “GPU threads” or kernel-invocations all executing in lock-step together(they are all sharing a program-counter, with the exception of execution masks, and are all executing the same kernel) within an SM. A turing SM is capable of executing 32 warps together in parallel(that’s 32 * 32 = 1024 gpu-threads, in parallel within any given SM).
- Vulkan/OpenCL calls it a
subgroup- Nvidia calls it a
warp- AMD calls it a
wavefrontThe interesting part about always having subgroups of
32threads always executing in parallel with each other is that you can have them each communicate, synchronize, and even share data with each other very quickly!
At any given moment, a single Streaming Multiprocessor is in the middle of executing 32 warps(again, 1024 threads), all at the same time. Depending on your architecture and CUDA compatibility, this number may differ a bit.
AMD hardware can chew through threads in groups of 64 rather than 32, thus their subgroupSize is 64 rather than 32.
So, on my GTX 1650, we’re expecting 16 Streaming-Multiprocessors, and each SM to have 32 warps per SM. And now with this extension we have a means to identify both the index of the SM([0,15]) and the identifier of the Warp executing within that SM([0,31]) within my particular GPU.
Here, I’ve repurposed one of my Adobe After Effects plugins to write these new shader builtins into the Red and Green channels of the image. The intensity of the color channel indicates index of the value within its respective domain.
From the spec:
Overview
This extension adds the functionality of NV_shader_thread_group
that was not subsumed by KHR_shader_subgroup.
In particular, this extension adds new shader inputs to query
* the number of warps running on a SM (gl_WarpsPerSMNV),
* the number of SMs on the GPU (gl_SMCountNV),
* the warp id (gl_WarpIDNV), and
* the SM id (gl_SMIDNV).
| Color Channel | Value |
|---|---|
| Red | gl_SMIDNV / gl_SMCountNV |
| Green | gl_WarpIDNV / gl_WarpsPerSMNV |
| Blue | 0 |
PixelColor.rgb = vec3(
gl_SMIDNV / float(gl_SMCountNV), // Red Channel
gl_WarpIDNV / float(gl_WarpsPerSMNV), // Green Channel
0
);
In Vulkan’s abstraction of these concepts, the GTX 1650 in my laptop exposes these details about itself.

maxComputeWorkGroupInvocations is the maximum amount of invocations(read: threads) that a single workgroup can have. This matches up precisely with the fact that a single Turing-SM can have a max of 1024 resident-threads.
So for a 2-Dimensional compute dispatch, I want some width * height = 1024 workgroup-size to fully occupy the SM with threads. Thankfully, most power-of-two numbers lend themselves to things like this. A sqrt(1024) will get me both a width and a height. sqrt(1024) = 32, so my workgroup size is 32 * 32 = 1024, which fully occupies each SM with 1024 threads. Now to dispatch enough 1024-thread-workgroups to account for every pixel of an image and ensuring that we emit an upper-bound in each dimension in case any of the image dimensions are smaller than 32 or not an even multiple of 32.
maxComputeWorkGroupInvocationsmay be different for your GPU.
...
const float OptimalWorkgroupSize2D = std::sqrt(maxComputeWorkGroupInvocations);
vkCmdDispatch( myCmdBuf,
std::uint32_t(std::ceil(imageWidth / OptimalWorkgroupSize2D)),
std::uint32_t(std::ceil(imageHeight / OptimalWorkgroupSize2D)),
1
);
...
So, lets do a 2D dispatch across the pixels of a blank 256x256 image a bunch of items to see how work is being distributed between runs.
A quick re-cap:
A Turing-
SMhas32warpsA warp has
32threadsWhich means a Turing-
SMcan have up to32 * 32 = 1024threads at any given momentVulkan exposes this value as
maxComputeWorkGroupInvocations, the largest number of threads(invocations) that can sustain the concept of aworkgroup.To process a
256x256image, and optimally utilize anSM’s1024-thread capabilities, we can distribute workgroups in 2D-groups of32x32 = 1024threads because32is the square-root of1024(maxComputeWorkGroupInvocations).
So for a 256x256 image we would do a 2D dispatch of 8 * 8 = 64 workgroups with each workgroup being the size 32x32x1. A total of 65536 invocations for this particular dispatch
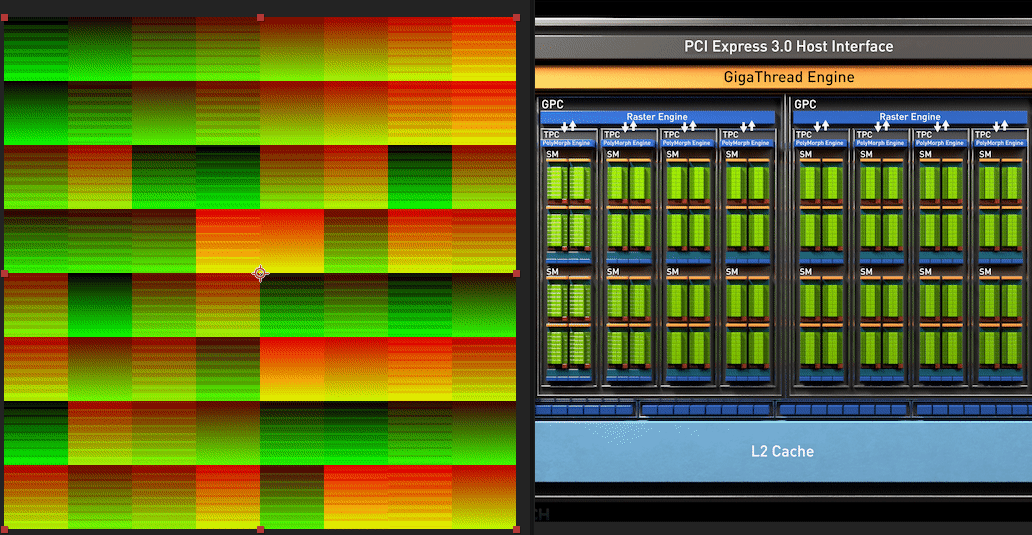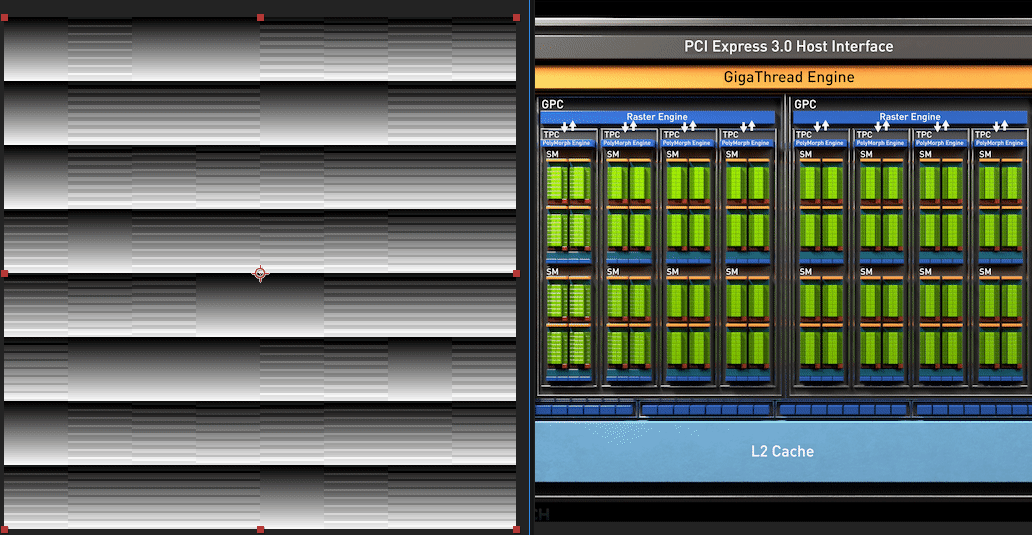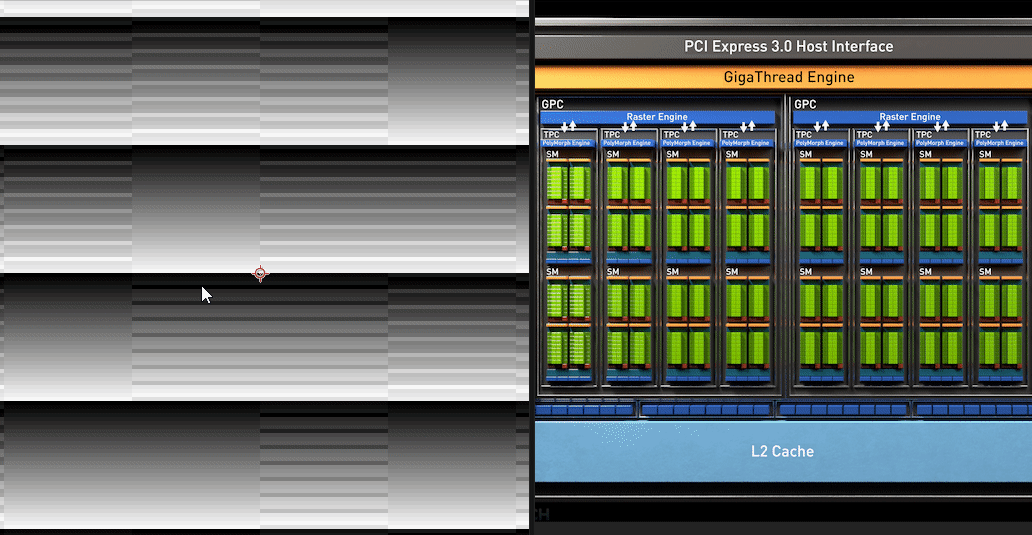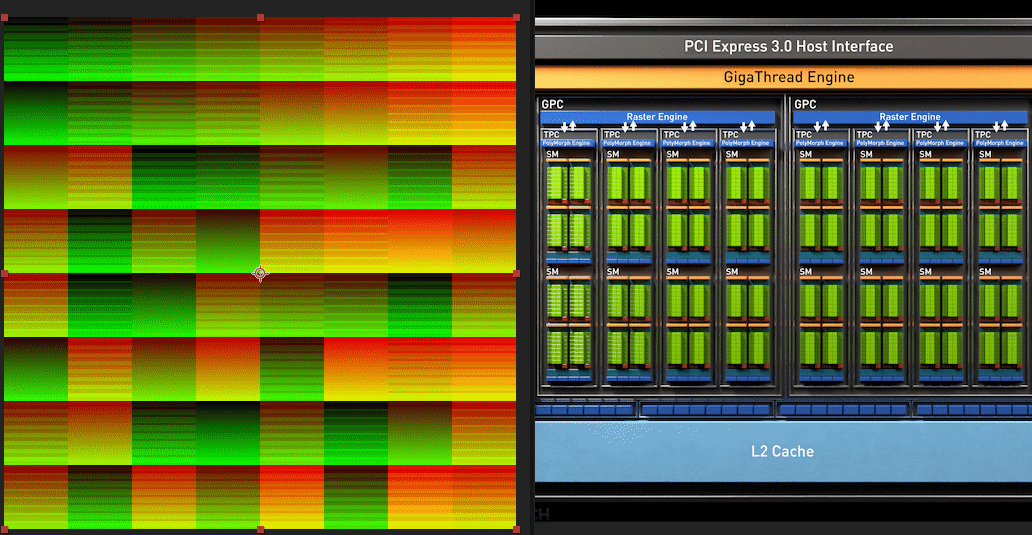
| Dispatch Result | Red Channel | Green Channel |
|---|---|---|
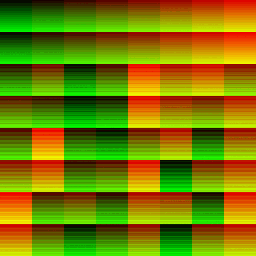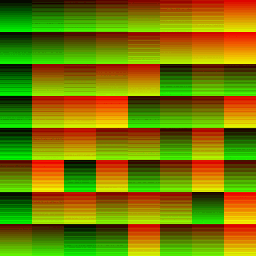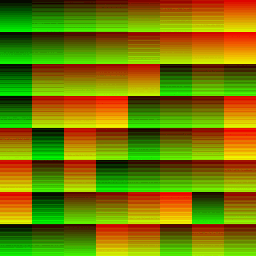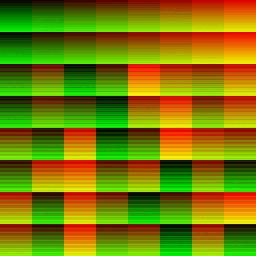 |
 |
 |
A lot’s happening here. I’ll zoom into a small 64x64 tile around the middle too to dissect what’s going on.
| Dispatch Result | Red Channel | Green Channel |
|---|---|---|
 |
 |
 |
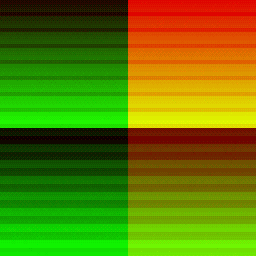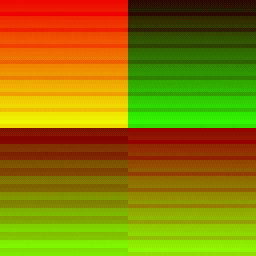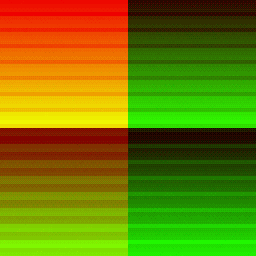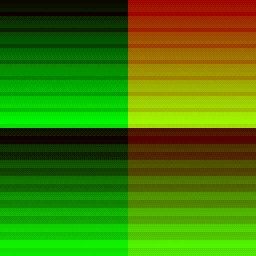
| Dispatch Red Channel | Zoomed/Slowed down |
|---|---|
|
|
A characteristic to notice in the Red channel of the full dispatch is that the first 16(this matches up precisely with the number of SM we were expecting on this chip) tiles at the top of the 2D compute dispatch has a steady ascending change in brightness(SM index is increasing).
The scheduler dispatched the SM very determinately, then after that it’s total noise as the scheduler has to take over and re-assigns the SM to work on another part of the dispatch based on which ever SM becomes available. The GPU only has 16 SM and we asked it to do 64 SM-worth of work, it has to make do.
| Dispatch Green Channel | Zoomed/Slowed down |
|---|---|
|
|
In the Green channel, we see regular horizontal streaks where the gl_WarpIDNV is consistent.
We see rows of 32 pixels that all have the same pixel intensity, where a group of 32-threads are all bundled together into a warp under the same gl_WarpIDNV.
We see columns of 32 pixels, each of seemingly randomly ordered intensity but where where each row identifies a unique bundle of a 32-thread warp.
The SM is scheduling its 32-warp-capacity across the vertical axis of this 32x32 tile, and each 32-thread-warp is taking up a full scanline on the horizontal axis.
Just for fun, I set the workgroup’s size to be 13 rather than 32.
Meaning each work-group is now going to be of size 13 * 13 = 169 and we will need to dispatch more workgroups to handle the entire 256x256 image.
I picked 13 since this is a nice and small prime number. Nothing will divide it evenly, especially in a world where hardware likes to work with power-of-two numbers.
So for a 256x256 image we would do a 2D dispatch of 20 * 20 = 400 workgroups with each workgroup being the size 13x13x1.
A total of 67600 invocations for this particular dispatch.
| Dispatch Result | Red Channel | Green Channel |
|---|---|---|
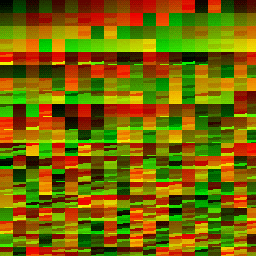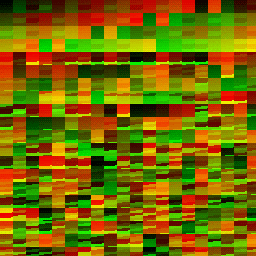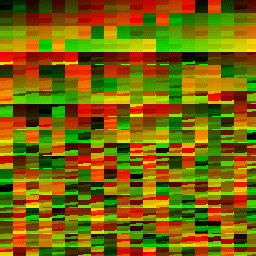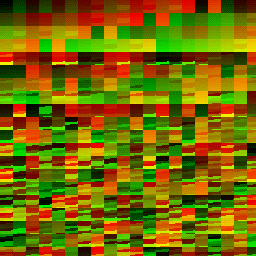 |
 |
 |
And here it is zoomed in on a particular 4x4 section of workgroups.
| Dispatch Result | Red Channel | Green Channel |
|---|---|---|
 |
 |
 |
This is a mess, but it’s actually not as bad as you think.
One
SMcan sustain1024threads, and we have a workgroup size of169, so eachSMcan sustain 6(floor(1024 / 169 = 6.059171597633136)) of our weird13x13x1workgroups.One of these
13x13x1workgroups will take the capacity of 6(ceil( 32 / 6 = 5.333333333333333)) warps.So at any given moment an
SMwill have 5 workgroups, each taking 6 warps each, utilizing 30(5 * 6 = 30) of the32-warp-capacity of the SM.At
30/32warp-usage,2of the32warps of anSMwill be unused. This is a under-utilization.
Surprisingly though, that means that we are utilizing 93.75% of the SM’s full capacity(30/32 = 0.9375). Which isn’t so bad, but we still had to dispatch 20x20=400 workgroups rather than the more-ideal 8x8=64 workgroups.
This is an example of what Nvidia calls occupancy.
Occupancy is the ratio of the number of active warps per multiprocessor to the maximum number of possible active warps.
| WorkgroupSize | |
|---|---|
| 1024 | 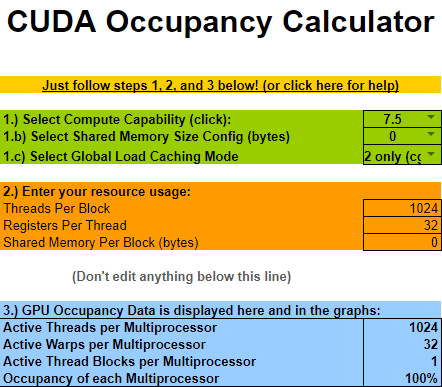 |
| 169 | 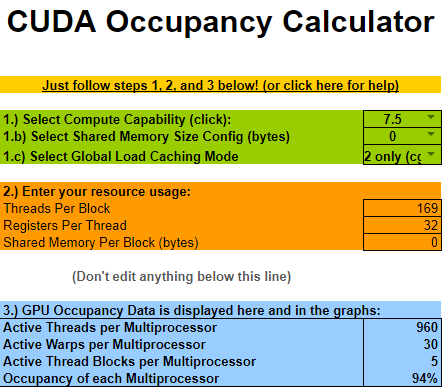 |
So if there is one thing to take away from all this it’s:
To achieve full chip-utilization in Vulkan:
Your workgroup size(
x * y * z) should be some multiple of your device’ssubgroupSize(Intel/Nvidia:32, AMD:64), but no greater thanmaxComputeWorkGroupInvocations.
