
This is a very subjective “please use this C++ feature”-post where I try to convince you to use user-literals to solve a particular issue of concisely declaring memory sizes.
You’ve probably seen or done stuff like this before in a code base when dealing with units of memory.
const std::size_t BUFFER_SIZE = 1024 * 1024 * 8;
...
const std::size_t ScratchSpace = 1000 * 1000 * 4;
...
#define KILOBYTES * 1024UL
#define MEGABYTES * 1048576UL
#define GIGABYTES * 1073741824UL
...
#define KILO * 1000
#define MEGA * (1000 * 1000)
#define GIGA * (1000 * 1000 * 1000)
...
#define KB(x) ((size_t) (x) << 10)
#define MB(x) ((size_t) (x) << 20)
...
const unsigned long KILOBYTE = 1024;
const unsigned long MEGABYTE = 1024 * 1024;
const unsigned long GIGABYTE = 1024 * 1024 * 1024;
const auto BUFFER_SIZE = MEGABYTE * 8;
I’ve certainly dealt with this enough to where I’ve wanted a much better pattern.
Counting the amount of 1024 * 1024 * ... in the expression to see if it’s counting
in KB/MB/GB or KiB/MiB/GiB does not easily lend itself to being reasoned with
quickly.
Having global preprocessors feels like a step in the right direction. You’ll be competing in the global namespace now and might conflict with other symbols since these substitutions occur within the textual-processing passes of compilation rather than within the intermediate representation of the C++ language itself.
Several competing libraries might globally define MEGABYTE as well and might even
define it by base-10(1000 * 1000 * ...) forcing you to #undef it within
particular translation units or do some other sort of trick to avoid this
global definition from poisoning your code base. Sound
familiar?
There is certainly a “base-10 or base-2 memory sizes-controversy going on where people will use units of 1000 or 1024 and call it “MB” and users have to guess if they mean base-10 or base-2 units when reading program output or setting up configuration files. The landscape is still quite confusing to this day.
Linux man pages disclaim that free software is heading in the direction of just showing both units in an attempt to recover from sloppy memory-size definitions of the past.
Ubuntu has a policy about when to use base-2 or base-10 units. Somewhat preferring base-10 in some contexts and base-2 in others.
This is beside the point of this post though, you can define the user-literals to your preference.
Personally, I just use
KiB/MiB/GiB/… everywhere and always use base-2 units to remove any discrepancy or confusion. You’ll see me using those moving forward.
User Literal memory sizes
The best solution I’ve personally found for this problem is User Literals.
User-literals, introduced in C++11, is a concise and modern way to declare units and literals of all sorts across your code base.
I’ve found it to solve this particular problem of memory-sizes quite well.
You can tuck it away into its own namespace and opt into using these literals
by putting using namespace MyLib::Literals into your scope(functions, classes,
structs, other namespaces). std::chrono does this pattern for its
time-based literals
since C++14. User-defined literals require an additional _-prefix at the
beginning to protect the C++ specification from conflicting with any
user-defined ones such as
ULL. So, you will
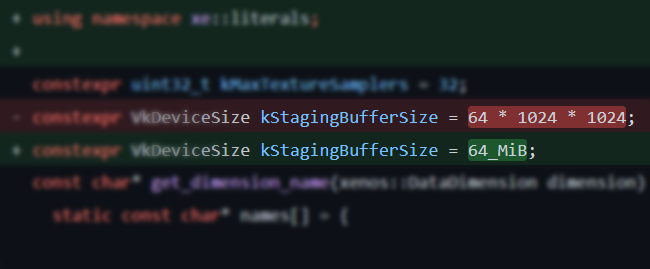
have to define your new literals as 6_GiB rather than 6GiB. Visually, I see this as a plus.
User-literals will allow your memory size definitions will be much more concise and readable, as well as your diagnostic messages(subjective):
const std::size_t BufferSize = 8_MiB;
...
std::byte LogBuffer[64_KiB];
...
Config.StackSize = 16_MiB;
...
class Foo {
public:
Foo() : memory_size_(64_MiB) {
...
std::size_t new_size = round_up(old_size, 64_KiB);
...
if( Size >= 1_GiB )
...
BufferThing(std::size_t InitialSize = 1_MiB);
...
const uint8_t BufferSize = 4_GiB;
// warning: implicit conversion from 'size_t' (aka 'unsigned long') to 'const uint8_t' (aka 'const unsigned char') changes value from 4294967296 to 0 [-Wconstant-conversion]
// const uint8_t BufferSize = 4_GiB;
// ~~~~~~~~~~ ^~~~~
And best of all, adding this feature to your codebase is very simple!
// namespace My::Cool::Library::Literals {
constexpr std::size_t operator""_KiB(unsigned long long int x) {
return 1024ULL * x;
}
constexpr std::size_t operator""_MiB(unsigned long long int x) {
return 1024_KiB * x;
}
constexpr std::size_t operator""_GiB(unsigned long long int x) {
return 1024_MiB * x;
}
constexpr std::size_t operator""_TiB(unsigned long long int x) {
return 1024_GiB * x;
}
constexpr std::size_t operator""_PiB(unsigned long long int x) {
return 1024_TiB * x;
}
// } // namespace My::Cool::Library::Literals
The largest integer-type that a custom-defined user-literal can accept is
unsigned long long int. So the parameter of this user-literal function isunsigned long long intrather than something likeuintmax_torsize_t.
Usage will depend on your context and if you have decided to make it available globally or tucked it away into a namespace.
If you defined it globally in one of your headers then you’re good to start
using it immediately anywhere! Just put ..._GiB and such where you are
intending to designate a size of memory.
If you put it within a namespace such as My::Cool::Library::Literals then you
can designate particular contexts or scopes where you want to use it with the
using-directive.
It works the same way that using namespace std does. Which you probably used
in school at some point while learning C++ before they told you to never do
it again.
The chrono header introduced literals using this
pattern since C++14
rather than just adding it to the global namespace so that you can choose when
and where these literals can become active.
Do you know you’ll be using it a lot across a particular file?
Then simply add using namespace My::Cool::Library::Literals near the top of
your file and you’re good to go. The literals will only be available within the
scope that you’ve declared the using namespace directive and it will not leak
outside of this file:
// Blah.cpp
using namespace My::Cool::Library::Literals;
void Foo(std::size_t Size)
{
const std::size_t PaddedSize = RoundUp(Size, 64_KiB);
...
}
Do you know you’ll be using it a lot within a particular function? Then you can put the using-directive right within the particular function:
// Blah.cpp
void Foo(std::size_t Size)
{
using namespace My::Cool::Library::Literals;
const std::size_t PaddedSize = RoundUp(Size, 64_KiB);
...
}
Try it out sometime! This can be very useful for lots of other types and units of measurements. Like if you have a particular unit of measurement for your game or software that you know you’ll be using everywhere or even compile-time string hashes of some kind.
Here are a couple of PRs that I’ve contributed that add these user literals:
