
gf2p8affineqb is becoming a new favorite. Previously I have a short introduction to the instruction and showed an example of it being used to reverse all 128-bits within a vector-register by first reversing the bits within each bytes, and then reversing the bytes.
For my next “trick”, I’ll implement some intrinsics that are curiously missing from the x86 ISA.
Lets say you’re doing some cool SIMD work and while you’re designing your kernels,
you find yourself needing to bit-shift some bytes around. Maybe you want to multiply
your vector of 8-bit integers by a power of two or something. You want to do a
logical shift left by some immediate value.
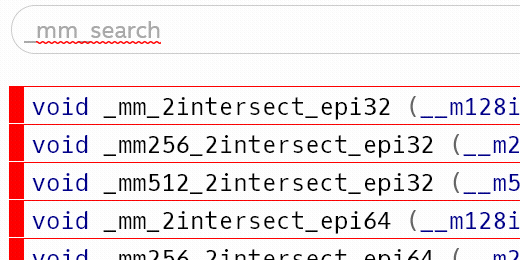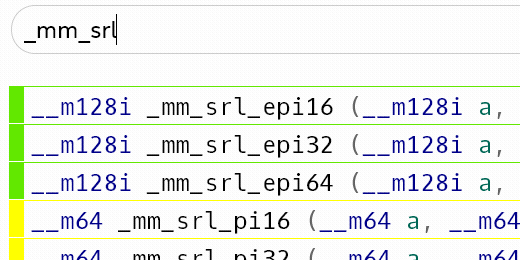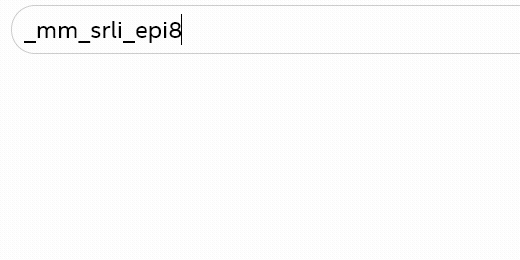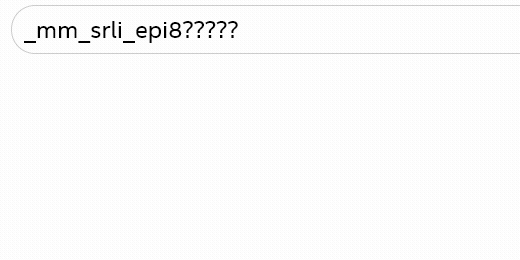
So you have the Intel Intrinsics Guide
open on the other screen like a good SIMD programmer and you curiously start
typing in _mm_srli_epi, hoping to see _mm_srli_epi8 at some point.
Yep, no _mm_srli_epi8, no _mm_slli_epi8, not even a _mm_srai_epi8.
epi16/32/64 gets plenty of ISA attention, but epi8 is pretty neglected.
Lets change that
With gf2p8affineqb, we can calculate matrices ahead of time or at runtime to
transform each byte to accomplish a bit-shift.
An identity matrix, that just takes in the bits and puts them where they were originally,
is just the 64-bit constant 0x0102040810204080.
[ 0 0 0 0 0 0 0 1 ] < Byte 7, Bit 0
[ 0 0 0 0 0 0 1 0 ] < Byte 6, Bit 1
[ 0 0 0 0 0 1 0 0 ] < Byte 5, Bit 2
X' = [ 0 0 0 0 1 0 0 0 ] < Byte 4, Bit 3 * X + 0
[ 0 0 0 1 0 0 0 0 ] < Byte 3, Bit 4
[ 0 0 1 0 0 0 0 0 ] < Byte 2, Bit 5
[ 0 1 0 0 0 0 0 0 ] < Byte 1, Bit 6
[ 1 0 0 0 0 0 0 0 ] < Byte 0, Bit 7
0b00000001'00000010'00000100'00001000'00010000'00100000'01000000'10000000
0x0102040810204080
In typical matrix fashion, each of the rows of the matrix determines how the resulting bits of the new 8-bit integer is defined. The bytes are defined in reverse order though, as the definition of the function defines its byte-indexing in reverse(
7 - i) order. Byte 0 defines how bit-7 is built, byte 1 defines how bit-6 is built, byte 2 defines how bit-5 is built, and so on.
So, if we wanted to simulate a single logical shift to the left by one bit as a matrix operation, the bit-0 row has to result in ‘0’, the bit-1 row has to retrieve the incoming-bit-0, the bit-2 row has to retrieve the incoming-bit-1, and so on:
A new matrix, that defines a logical shift to the left by 1 bit.
[ 0 0 0 0 0 0 0 0 ] < Byte 7, Bit 0
[ 0 0 0 0 0 0 0 1 ] < Byte 6, Bit 1
[ 0 0 0 0 0 0 1 0 ] < Byte 5, Bit 3
X' = [ 0 0 0 0 0 1 0 0 ] < Byte 4, Bit 3 * X + 0
[ 0 0 0 0 1 0 0 0 ] < Byte 3, Bit 4
[ 0 0 0 1 0 0 0 0 ] < Byte 2, Bit 5
[ 0 0 1 0 0 0 0 0 ] < Byte 1, Bit 6
[ 0 1 0 0 0 0 0 0 ] < Byte 0, Bit 7
0b00000000'00000001'00000010'00000100'00001000'00010000'00100000'01000000
0x0001020408102040
Here’s one to the right by 2 bits too:
A new matrix, that defines an arithmetic shift to the right by 2 bits
[ 0 0 0 0 0 1 0 0 ] < Byte 7, Bit 0
[ 0 0 0 0 1 0 0 0 ] < Byte 6, Bit 1
[ 0 0 0 1 0 0 0 0 ] < Byte 5, Bit 3
X' = [ 0 0 1 0 0 0 0 0 ] < Byte 4, Bit 3 * X + 0
[ 0 1 0 0 0 0 0 0 ] < Byte 3, Bit 4
[ 1 0 0 0 0 0 0 0 ] < Byte 2, Bit 5
[ 0 0 0 0 0 0 0 0 ] < Byte 1, Bit 6 < Repeat bit 7
[ 0 0 0 0 0 0 0 0 ] < Byte 0, Bit 7 < Repeat bit 7
0b00000100'00001000'00010000'00100000'01000000'10000000'00000000'00000000
0x408102040800000
And if you look closely at the matrix constants:
Identity-Matrix: 0x0102040810204080
"Logical shift left once"-Matrix: 0x0001020408102040
"Logical shift right twice"-Matrix: 0x0408102040800000
An 8-bit logical shift left by n bits is bit-shifting the identity matrix itself to the right by i*8 bits!
An 8-bit logical shift right by n bits is bit-shifting the identity matrix itself to the left by i*8 bits!
And with that, both _mm_slli_epi8 and _mm_srli_epi8 can be derived!
inline __m128i _mm_slli_epi8(__m128i a, std::uint8_t imm8)
{
return _mm_gf2p8affine_epi64_epi8(
a, _mm_set1_epi64x(0x0102040810204080 >> (imm8 * 8)), 0
);
}
inline __m128i _mm_srli_epi8(__m128i a, std::uint8_t imm8)
{
return _mm_gf2p8affine_epi64_epi8(
a, _mm_set1_epi64x(0x0102040810204080 << (imm8 * 8)), 0
);
}
So what about _mm_srai_epi8? An arithmetic shift is different in that not only
do we shift the bits to the right, but we also replicate the most significant bit
to preserve signed-ness of the original integer. So an arithmetic shift to the
right by two bits means that we do a logical shift to the right twice, but rather
than shifting in new 0-bits we want to repeat the bit in bit-7.
A new matrix, that defines an arithmetic shift to the right by 2 bits
[ 0 0 0 0 0 1 0 0 ] < Byte 7, Bit 0
[ 0 0 0 0 1 0 0 0 ] < Byte 6, Bit 1
[ 0 0 0 1 0 0 0 0 ] < Byte 5, Bit 3
X' = [ 0 0 1 0 0 0 0 0 ] < Byte 4, Bit 3 * X + 0
[ 0 1 0 0 0 0 0 0 ] < Byte 3, Bit 4
[ 1 0 0 0 0 0 0 0 ] < Byte 2, Bit 5
[ 1 0 0 0 0 0 0 0 ] < Byte 1, Bit 6 < Repeat bit 7
[ 1 0 0 0 0 0 0 0 ] < Byte 0, Bit 7 < Repeat bit 7
0b00000100'00001000'00010000'00100000'01000000'10000000'10000000'10000000
0x408102040808080
Compared to the other constants-
Identity-Matrix: 0x0102040810204080
"Logical shift left once"-Matrix: 0x0001020408102040
"Logical shift right twice"-Matrix: 0x0408102040800000
"Arithmetic shift right twice"-Matrix: 0x0408102040808080
-the only difference this has from the the matrix bit-shifting for the
logical shift right, is that while we shift the identity matrix to the left by
i * 8 bits, we also shift in bytes of 0x80!
So after we bit-shift the identity matrix like the logical-step, we want to do a
logical OR of this matrix with a i bytes of 0x80 to sign-extend the
bytes:
inline __m128i _mm_srai_epi8(__m128i a, std::uint8_t imm8)
{
// Shift a mask of 1111... bits to the left, invert it, and use this to mask
// against 0x808080... to generate our sign-extended matrix elements
// Latest compilers and architectures will reduce this into a `bzhi`
// instruction
const std::uint64_t sign_extend = ~(0xFFFFFFFFFFFFFFFF << (imm8 * 8)) & 0x8080808080808080;
return _mm_gf2p8affine_epi64_epi8(
a,
// Perform a logical shift right, but shift in 0x80 bytes
// to replicate the most significant bit
_mm_set1_epi64x(
0x0102040810204080 << (imm8 * 8)
// Simulate shifting in 0x80 bytes by doing a bit-wise OR
// against masked 0x80 bytes
| sign_extend
// If you're targetting a BMI2-enabled environment, you can
// use bzhi directly too
//| _bzhi_u64(0x8080808080808080ull, imm8 * 8) // BMI2
),
0
);
}
And with that, all the missing epi8 bit-shifting functions. Ready to copy-paste.
// If you are unable to guarantee that 'imm8' is properly bounded to [0,8)
// then uncomment the safety-check lines at the top of each function to safely
// handle invalid shift-values of imm8. See final note
inline __m128i _mm_slli_epi8(__m128i a, std::uint8_t imm8)
{
// if(imm8 > 7) return _mm_setzero_si128();
return _mm_gf2p8affine_epi64_epi8(
a, _mm_set1_epi64x(0x0102040810204080 >> (imm8 * 8)), 0
);
}
inline __m128i _mm_srli_epi8(__m128i a, std::uint8_t imm8)
{
// if(imm8 > 7) return _mm_setzero_si128();
return _mm_gf2p8affine_epi64_epi8(
a, _mm_set1_epi64x(0x0102040810204080 << (imm8 * 8)), 0
);
}
inline __m128i _mm_srai_epi8(__m128i a, std::uint8_t imm8)
{
// imm8 = imm8 > 7 ? 7 : imm8;
const std::uint64_t sign_extend = ~(0xFFFFFFFFFFFFFFFF << (imm8 * 8)) & 0x8080808080808080;
return _mm_gf2p8affine_epi64_epi8(
a,
_mm_set1_epi64x(0x0102040810204080 << (imm8 * 8) | sign_extend), 0
);
}
A final note, these functions assume you are only passing in valid shift values
for the imm8 argument(shift-values of [0,8)). Due to the arithmetic of
generating the matrix, passing in values larger than the acceptable range of values
is considered undefined behavior in C and C++.
So, uint64(x) << imm8 * 8, where imm8 >= 8 is undefined, which the matrix
calcuation seen here is susceptible to.
On x86, bit-shift instructions will only interpret the lower bits of your shift-value
for the value-type that is being shifted. So trying to bit-shift a 32-bit register
by 35 would equate to shifting it by 4, because it will only interpret the
lower 5 bits of your shift value(modulo-32). This would be how the undefined-behavior
would manifest itself on x86, which is not desirable.
Logical shifting an 8 bit value by 2000 should simply be 0, and arithmetic shift-overflows should behave just like the shift-by-7 case(the 7th bit is copied to all other bits).
I used these functions to accelerate the yuzu emulator’s ARM-recompiler backend!
