
In a previous post, I used Intel’s AMX instructions intended for AI/ML use-cases to take the average color of an image. This was primarily a proof-of-concept since pedestrians like me generally don’t have access to Intel’s’ AMX-enabled hardware. The cost-of-entry for Intel’s Sapphire Rapids chips is pretty steep too. Maybe some day it will be ubiquitous in consumer-hardware and share a similar story as AVX-512.
Pedestrians like me do have access to an Apple M2 Mini though, after some frustration with trying to sustain a development-environment with a MacOS VM:
Apple M2 with 8-core CPU, 10-core GPU, 16‑core Neural Engine, 8GB unified memory
My “build server” for porting software to MacOS, since a VM wasn’t cutting it anymore.
Liquid Death for scale

AMX
These chips, confusingly, also have an instruction set referred to as “AMX” for AI/ML use-cases, sharing the same name-space as Intel’s AMX instructions.
This instruction set has been reverse-engineered as an open-source effort from the Apple-Clang compiler symbols, the iOS SDK, and other sources.
Similar to Intel’s AMX, the Apple AMX state is composed of very large registers
addressed in two dimensions.
In Apple’s AMX, these are the X, Y, and Z register-pools.
A single register within these register-pools addresses a 64-byte “row” of
elements.
The X and Y register-pool has 8 of these rows, and the Z register has
64 rows.
The entire contents of the Z register alone is 4KiB!
// A 64 byte "row" of elements
union amx_reg
{
std::uint8_t u8 [64];
std::uint16_t u16[32];
std::uint32_t u32[16];
std::int8_t i8 [64];
std::int16_t i16[32];
std::int32_t i32[16];
std::float16_t f16[32];
std::float32_t f32[16];
std::float64_t f64[ 8];
};
struct amx_state
{
amx_reg x[ 8]; // 64 bytes * 8 rows = 512 bytes
amx_reg y[ 8]; // 64 bytes * 8 rows = 512 bytes
amx_reg z[64]; // 64 bytes * 64 rows = 4096 bytes
};
The instructions themselves will encode how the rows bytes are to be interpreted.
The actual AMX hardware itself can almost be thought of as a “co-processor” shared among the regular cores. Each E-Core and P-Core cluster gets one “AMX core” each. This limits the degree of parallelism you might anticipate depending on how your AMX workload is actually scheduled. You’ll find some interesting consequences from the way this is designed, as it is another “client” of the L2 cache among the other cores.
M2 die shot by Locuza

Average Color
Again, like with Intel’s AMX instructions, I’ll try to find a way to utilize these instructions to help determine the average color of an image and see how much it improves over a few other implementations.
Generic implementation
Here is a generic implementation: Each RGBA8 pixel is unpacked, and then it’s byte-values are added into a much larger 64-bit sum, generally safe from over-flow issues.
// For illustration purposes it is assumed you are providing an image in
// linear color-space. If your image is in an sRGB color-space be sure to
// convert it to linear!
std::uint32_t AverageColorRGBA8(
const std::uint32_t Pixels[],
std::size_t Count
)
{
std::uint64_t RedSum, GreenSum, BlueSum, AlphaSum;
RedSum = GreenSum = BlueSum = AlphaSum = 0;
for( std::size_t i = 0; i < Count; ++i )
{
const std::uint32_t& CurColor = Pixels[i];
AlphaSum += static_cast<std::uint8_t>( CurColor >> 24 );
BlueSum += static_cast<std::uint8_t>( CurColor >> 16 );
GreenSum += static_cast<std::uint8_t>( CurColor >> 8 );
RedSum += static_cast<std::uint8_t>( CurColor >> 0 );
}
RedSum /= Count;
GreenSum /= Count;
BlueSum /= Count;
AlphaSum /= Count;
return
(static_cast<std::uint32_t>( (std::uint8_t)AlphaSum ) << 24 ) |
(static_cast<std::uint32_t>( (std::uint8_t) BlueSum ) << 16 ) |
(static_cast<std::uint32_t>( (std::uint8_t)GreenSum ) << 8 ) |
(static_cast<std::uint32_t>( (std::uint8_t) RedSum ) << 0 );
}
On clang 18.1.0 with -O2 and an increasing amount of mega-pixels, this
generic code performs pretty okay!
It’s a clean linear relationship where every 4 megapixels takes about
1 millisecond.
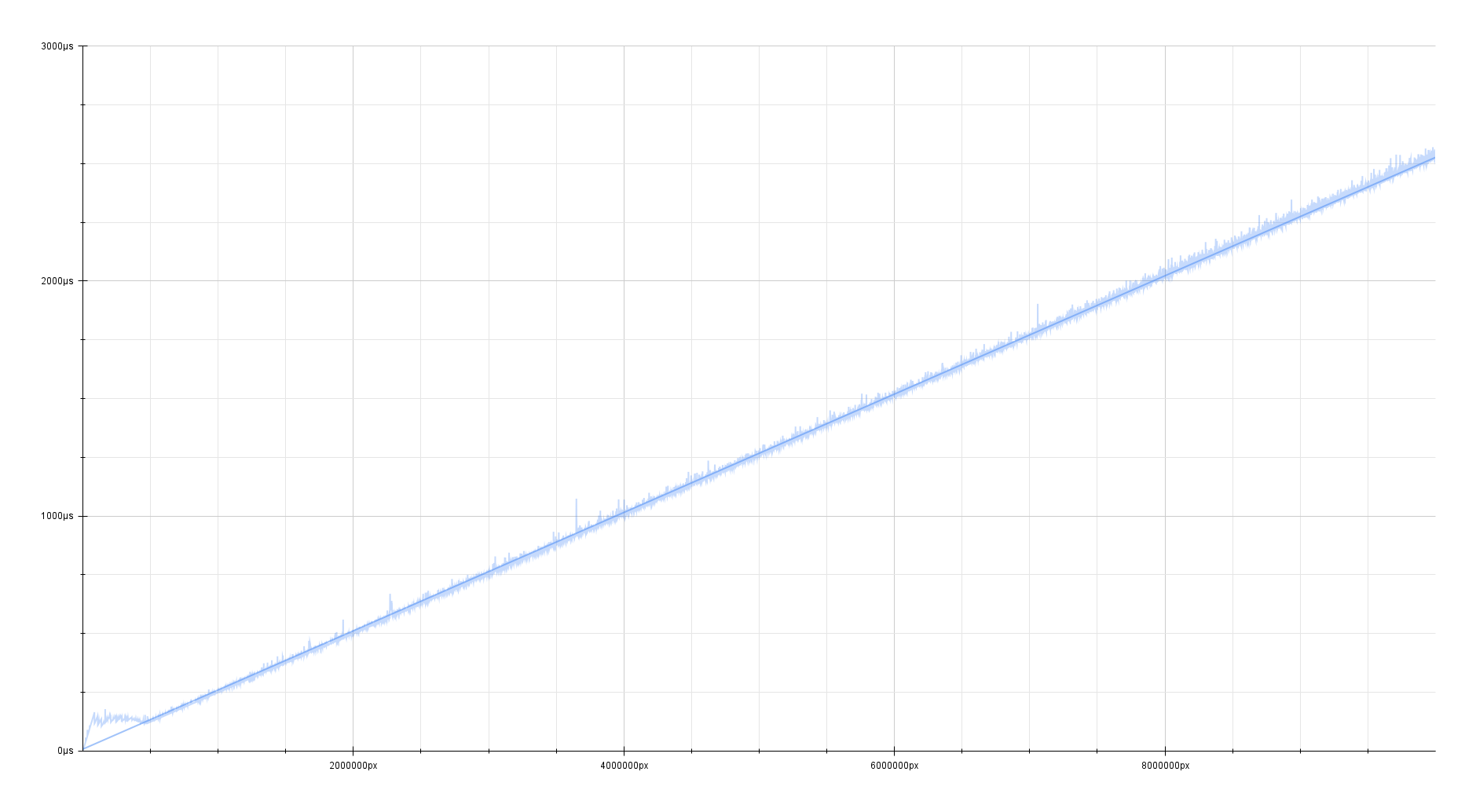
| Algorithm | Speed |
|---|---|
| Generic | ~4 megapixels/ms |
UDOT/UADDW{,2}
As a small aside, I also have two other implementations where I utilize UDOT
and UADDW{,2} to try and speed up this generic code on ARMv8.
They principally follow the idea of using SIMD to accumulate lanes of bytes
into larger 16/32-bit sums, and then summing those sums into a larger
sum every now-and-then to protect against integer over-flow.
The UDOT implementation can be seen here.
The UADDW{,2} implementation can be seen here.
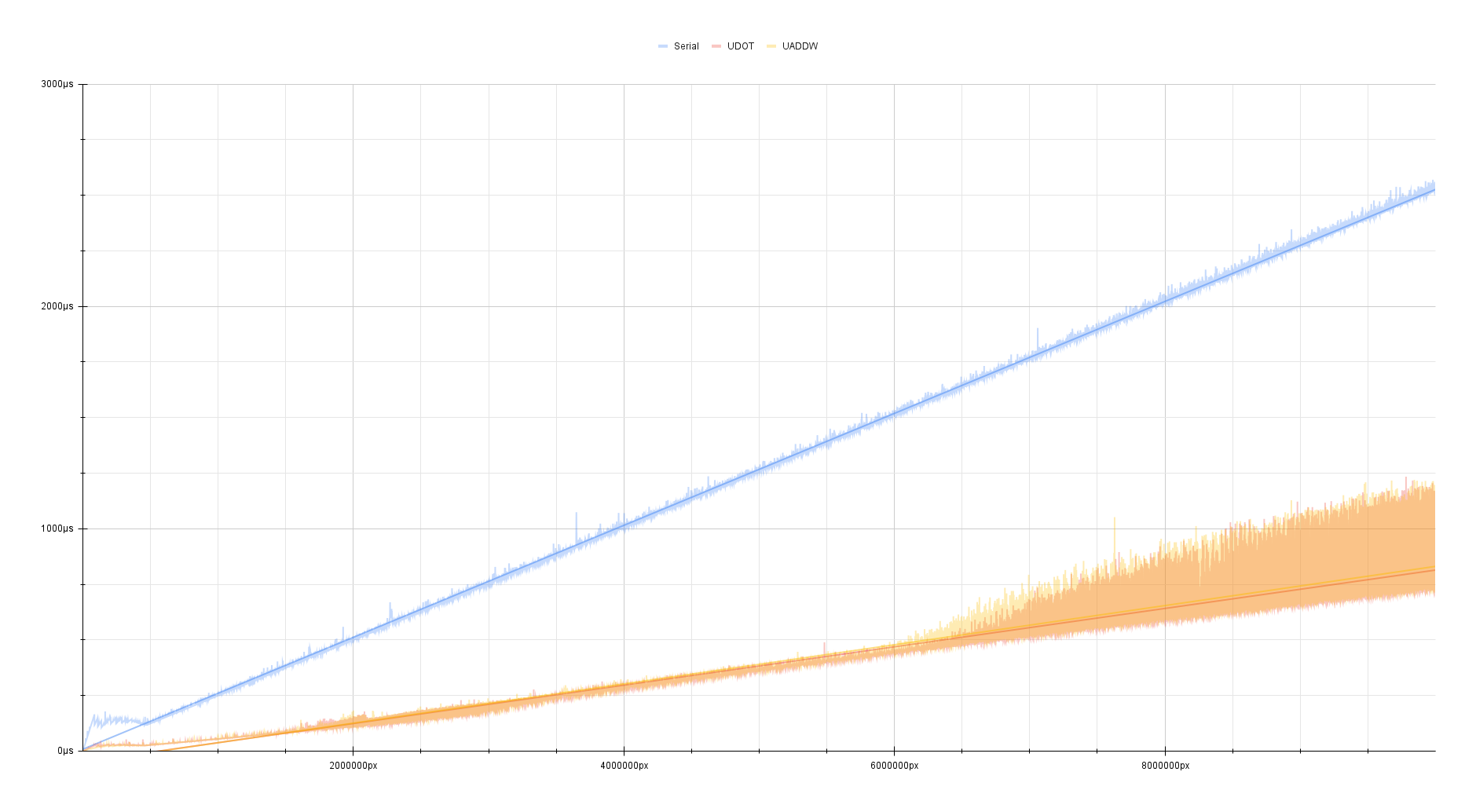
| Algorithm | Speed |
|---|---|
| Generic | ~4 megapixels/ms |
UDOT/UADDW |
~13.33 megapixels/ms |
Against the generic code, the speedup is pretty substantial. It’s about three
times faster!
Both the UDOT and UADDW implementations perform about the same and likely
saturate the same execution units.
At around 6 megapixels, around 22.89 MiB, the timing also seems to get very
noisy.
This is very likely a sign of this algorithm being memory-bound or an artifact
of being scheduled off to other cores after a certain amount of execution time.
Even with the noise, it is still consistently much faster than the generic code.
This is probably the kind of implementation you want to be using in your code base when targeting 64-bit ARM.
But! I’m trying to be quirky here and use AI instructions for something that isn’t strictly AI-related. If this was just about making this algorithm faster, the blog post would have ended here.
vecint(AMX)
This is the main-event of this post. I’ll step through the implementation details.
If you scroll through the list of AMX instructions, I was looking for something
that involves large 8-bit additions across many elements at once at some
point and ideally sums into a larger data-type without any lossy overflow issues.
There is also the matter of unpacking the individual RGBA channels at some
point, which ideally is not a part of the main loop.
The one that stood out to me the most for this particular use-case is
vecint.
Like most AMX instructions, the vecint instruction just takes a singular
64-bit General-Purpose-Register.
vecint will generally do an z[_][i] ±= f(x[i], y[i])-operation.
The f(...)-operation itself and data-types and such is further configured by
the 64 bits of the input register.
I’ve marked up the parts that we care about:
Operand bitfields
Used Bit Width Meaning Notes ✅ (47=4) 63 1 Z is signed ( 1) or unsigned (0)✅ (47≠4) 63 1 X is signed ( 1) or unsigned (0)✅ 58 5 Right shift amount Ignored when ALU mode in {5, 6} - 57 1 Ignored - 54 3 Must be zero No-op otherwise - 53 1 Indexed load ( 1) or regular load (0)- (53=1) 52 1 Ignored - (53=1) 49 3 Register to index into - (53=1) 48 1 Indices are 4 bits ( 1) or 2 bits (0)- (53=1) 47 1 Indexed load of Y ( 1) or of X (0)✅ (53=0) 47 6 ALU mode - 46 1 Ignored ✅ 42 4 Lane width mode Meaning dependent upon ALU mode - 41 1 Ignored - (31=1) 35 6 Ignored - (31=1) 32 3 Broadcast mode - (31=0) 38 3 Write enable or broadcast mode - (31=0) 32 6 Write enable value or broadcast lane index Meaning dependent upon associated mode ✅ 31 1 Perform operation for multiple vectors ( 1)
or just one vector (0)M2 only (always reads as 0on M1)- (47=4) 30 1 Saturate Z ( 1) or truncate Z (0)- (47=4) 29 1 Right shift is rounding ( 1) or truncating (0)- (47≠4) 29 2 X shuffle - 27 2 Y shuffle - (47=4) 26 1 Z saturation is signed ( 1) or unsigned (0)✅ (47≠4) 26 1 Y is signed ( 1) or unsigned (0)✅ (31=1) 25 1 “Multiple” means four vectors ( 1)
or two vectors (0)Top two bits of Z row ignored if operating on four vectors - 20 6 Z row Low bits ignored in some lane width modes
When 31=1, top bit or top two bits ignored- 19 1 Ignored - 10 9 X offset (in bytes) - 9 1 Ignored - 0 9 Y offset (in bytes) Marked up table from corsix/amx/vecint.md
For the Lane-Width mode: There is an option that will treat the input X and
Y operands as unsigned 8-bit integers, and the values in Z as 32-bit integers.
Bits 63 and 26 indicate that these values are to be considered unsigned.
Used X Y Z 42 - i16 or u16 i16 or u16 i32 or u32 (two rows, interleaved pair) 3✅ i8 or u8 i8 or u8 i32 or u32 (four rows, interleaved quartet) 10- i8 or u8 i8 or u8 i16 or u16 (two rows, interleaved pair) 11- i8 or u8 i16 or u16 (each lane used twice) i32 or u32 (four rows, interleaved quartet) 12- i16 or u16 (each lane used twice) i8 or u8 i32 or u32 (four rows, interleaved quartet) 13- i16 or u16 i16 or u16 i16 or u16 (one row) anything else Marked up table from corsix/amx/vecint.md
For the ALU mode, the actual operation is configured.
With the previously defined bits, we have two u8 operands from X and Y,
and a u32 value in Z.
Used Integer operation 47 Notes - z+((x*y)>>s)0- z-((x*y)>>s)1✅ z+((x+y)>>s)2Particular write enable mode can skip xory- z-((x+y)>>s)3Particular write enable mode can skip xory- z>>sorsat(z>>s)4Shift can be rounding, saturation is optional - sat(z+((x*y*2)>>16))5Shift is rounding, saturation is signed - sat(z-((x*y*2)>>16))6Shift is rounding, saturation is signed - (x*y)>>s10M2 only - z+(x>>s)11M2 only (on M1, consider 47=2 with skipped y)- z+(y>>s)12M2 only (on M1, consider 47=2 with skipped x)- no-op anything else Marked up table from corsix/amx/vecint.md
We effectively want to do Z += X + Y which maps closest to z+((x+y)>>s).
The s argument is an additional right-shift that can be applied from the
5-bit integer at bit-position 58.
In our case though, it is left at 0, so this effectively maps to
z+((x+y)>>0) = z+(x+y).
The way this operation is configured now, each byte from a row X and Y
will be added together and get its own unique 32-bit sum to accumulate to in
Z.
Because each byte is effectively expanded and added to a four-byte sum the
results in Z have to be spread out across multiple rows to accommodate the
data-type expansion.
So one row of bytes in X and Y will map to four rows of 32-bit sums in
Z.
It also de-interleaves every four bytes across these rows, so we get unpacked RGBA channels for free!
- Row 0 of inputs
X/Ywill map to rows0..3ofZ- Each byte of each
RGBA-element is spread across each of the four rows:0:R1:G2:B3:A
- Each byte of each
So with each iteration of vecint, we process process 16-pixels in X and
16-pixels in Y for a total of 32-pixels of input and mapping to
16 32-bit sums in Z of output. In just one instruction!
But, we have 8 rows in X and Y and 64 rows in Z that could be utilized
more.
We could always just emit the instruction several times and index into the
additional rows of X and Y with the 9-bit integers at bit-positions 0 and
10.
But, the M2 chip in particular supports some additional bulk-processing
configurations to processes even more data at a time in just one instruction:
Operand bitfields
Used Bit Width Meaning Notes - … … … ✅ 31 1 Perform operation for multiple vectors ( 1)
or just one vector (0)M2 only (always reads as 0on M1)- … … … ✅ (31=1) 25 1 “Multiple” means four vectors ( 1)
or two vectors (0)Top two bits of Z row ignored if operating on four vectors - … … … Marked up table from corsix/amx/vecint.md
Setting bit 31 indicates that this one instruction will now process two rows
of input rather than just one.
The M2 in particular adds bit 25 which further configures this instruction
to process four rows of input at a time rather than just two!
Each of the “multiple”-operation will separate the rows of output by 16 rows:
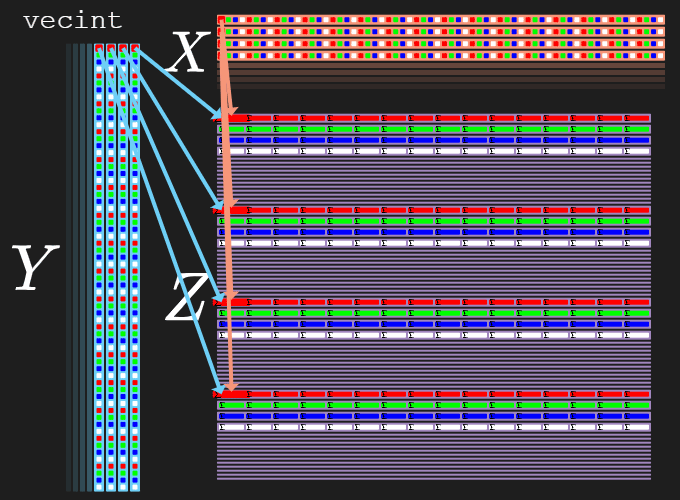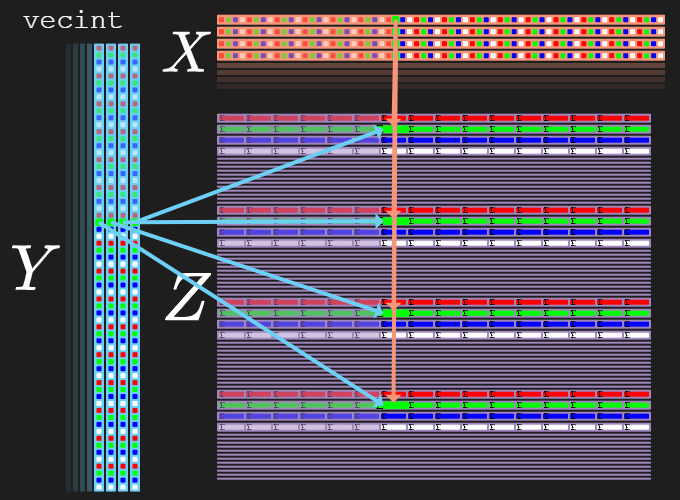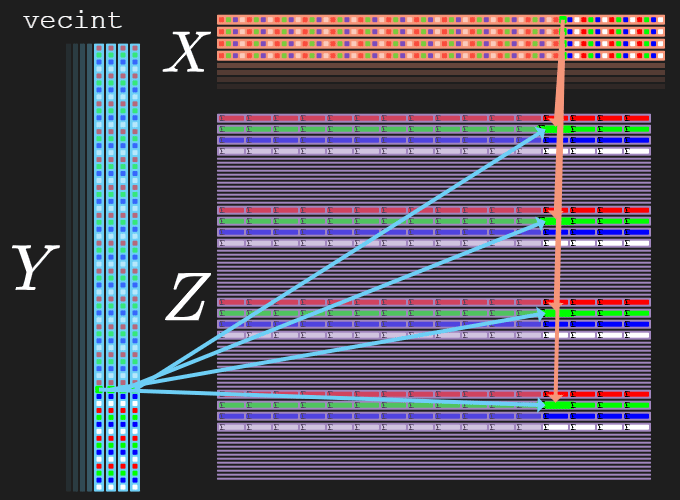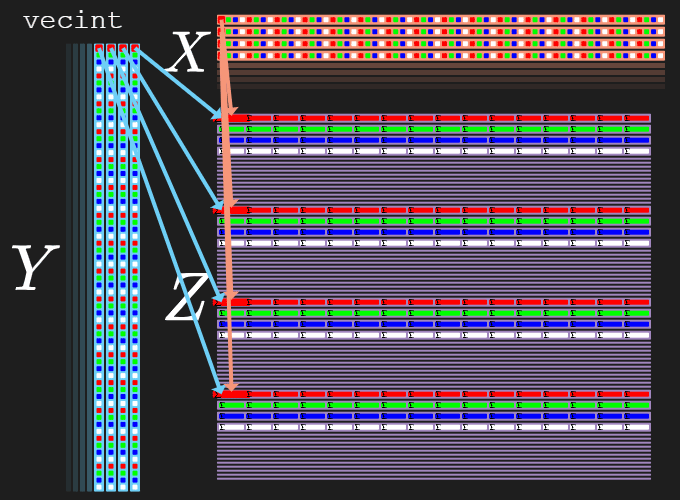
- Row 0 of inputs
X/Ywill map to rows0..3ofZ- Each byte of each
RGBA-element is spread across each of the four rows:0:R1:G2:B3:A
- Each byte of each
- Row 1 of inputs
X/Ywill map to rows16..19ofZ- Each byte of each
RGBA-element is spread across each of the four rows:16:R17:G18:B19:A
- Each byte of each
- Row 2 of inputs
X/Ywill map to rows32..35ofZ- Each byte of each
RGBA-element is spread across each of the four rows:32:R33:G34:B35:A
- Each byte of each
- Row 3 of inputs
X/Ywill map to rows48..51ofZ- Each byte of each
RGBA-element is spread across each of the four rows:48:R49:G50:B51:A
- Each byte of each
So at the end of our loop, there will be a one-time tango that has to be done to unpack these RGBA 32-bit sums into our larger 64-bit sums.
So with each iteration of vecint, we process process 64-pixels in X and
64-pixels in Y for a total of 128-pixels of input and mapping to
64 32-bit sums in Z of output. In just one instruction!
The instructions to actually load data into X and Y also support these additional
bulk-processing configurations.
The M2 in particular supports loading four rows of data at a time, while the
baseline instruction supports just one or two.
For
ldx/ldy:
Used Bit Width Meaning - 63 1 Ignored ✅ 62 1 Load multiple registers ( 1) or single register (0)- 61 1 On M1/M2: Ignored (loads are always to consecutive registers)
On M3: Load to non-consecutive registers (1) or to consecutive registers > (0)✅ 60 1 On M1: Ignored (“multiple” always means two registers)
On M2/M3: “Multiple” means four registers (1) or two registers (0)- 59 1 Ignored - 56 3 X / Y register index - 0 56 Pointer Marked up table from corsix/amx/ldst.md
With this, the main loop is just a very tight three instructions:
- Load 64 pixels into
X - Load 64 pixels into
Y - Perform
vecint(Z += X + Y)
At the end of the loop, and every now and then to protect from overflow, the
sums in Z have to be written to memory and unpacked and added into the larger
64-bit sums.
There is only one bit of configuration for storing two rows of Z at a time.
For
ldz/stz:
Bit Width Meaning 63 1 Ignored 62 1 Load / store pair of registers ( 1) or single register (0)56 6 Z row 0 56 Pointer Marked up table from corsix/amx/ldst.md
Once the rows are stored, there is some additional work to be done to add them
to the outer 64-bit sums, while protecting from integer-overflow.
This part of the process is a little ugly, but it’s also very infrequent.
You either do this once at the end of your loop, or every 16'843'009
iterations(~17 mega-pixels) to protect against overflow.
Thankfully, since vecint already de-interleaves the RGBA channels, each row
will only have R, G, B, or A-sums within it!
So just one more horizontal-addition of 32-bit sums needs to be done.
This can be accelerated with pair-wise widening-additions like with
vpaddlq_u32, vpadalq_u32 and a final vaddvq_u64 to add safely add up all
of the 32-bit sums into a larger 64-bit one without any worry of overflow.
The final implementation:
std::uint32_t AverageColorRGBA8(const std::uint32_t Pixels[], std::size_t Count)
{
std::size_t i = 0;
std::uint64_t RedSum = 0ULL;
std::uint64_t GreenSum = 0ULL;
std::uint64_t BlueSum = 0ULL;
std::uint64_t AlphaSum = 0ULL;
// 128 pixels at a time!
for( std::size_t j = i / 128; j < Count / 128; j++ )
{
// Required before any AMX instructions
AMX_SET();
// In the worst case, where all the bytes are just 0xFF being summed
// into a 32-bit accumulator, the 32-bit sum may overflow unless we
// ensure all 32-bit overflow-hazards are protected against.
// In this case: `(0xFFFFFFFF / 0xFF == 0x1010101` is the max amount of
// bytes we could ever safely accumulate into a 32-bit integer before we
// have to flush it into a larger data-type
constexpr std::size_t LocalSumOverflowMax = (0xFFFFFFFF / 0xFF);
for( std::size_t k = 0; (k < LocalSumOverflowMax) && (j < Count / 128);
k++, j++, i += 128 )
{
// Load 64 pixels into X
AMX_LDX(
reinterpret_cast<std::uintptr_t>((const uint8_t*)&Pixels[i + 0])
| (1ULL << 62) // Load multiple times
| (1ULL << 60) // Load four times
);
// Load another 64 pixels into Y
AMX_LDY(
reinterpret_cast<std::uintptr_t>((const uint8_t*)&Pixels[i + 64]
)
| (1ULL << 62) // Load multiple times
| (1ULL << 60) // Load four times
);
constexpr std::uint64_t VecIntOp =
// ALU mode
// 2 : f = Z+(X + Y) >> s
((2ULL) << 47) |
// Lane width mode:
// 10: Z.u32[i] += f(X.u8[i], Y.u8[i])
// Produces 64 32-bit integers, requiring 256 bytes of data
// total! four rows of Z: interleaved quartet(perfect for
// RGBA!):
((10ULL) << 42) |
// Iterate multiple times (M2 only)
((1ULL) << 31) |
// Iterate x4 times (M2 only)
((1ULL) << 25);
// Add each 64-bit value into a 32-bit sum across four rows of Z
// Z0 + Iter * 16: RSum32, RSum32, RSum32, RSum32, RSum32...
// Z1 + Iter * 16: GSum32, GSum32, GSum32, GSum32, GSum32...
// Z2 + Iter * 16: BSum32, BSum32, BSum32, BSum32, BSum32...
// Z3 + Iter * 16: ASum32, ASum32, ASum32, ASum32, ASum32...
AMX_VECINT(VecIntOp);
}
// Each row is full of 32-bit sums for the R, G, B, or A channel
uint32x4x4_t ZMat[4 * 4] = {{}};
for( std::size_t IterationIndex = 0; IterationIndex < 4;
++IterationIndex )
{
for( std::size_t ZRow = 0; ZRow < 4; ZRow += 2 )
{
// Store pairs-of-rows of Z(64 bytes x 2)
AMX_STZ(
reinterpret_cast<std::uintptr_t>(&ZMat[ZRow + 4 * IterationIndex])
| static_cast<std::uint64_t>(ZRow + 16 * IterationIndex) << 56
| 1ULL << 62
);
}
}
// Should be used when done with any AMX processing.
// Think of it like `vzeroupper` from AVX
AMX_CLR();
for( std::size_t IterationIndex = 0; IterationIndex < 4;
++IterationIndex )
{
const std::size_t IterationOffset = IterationIndex * 4;
// Widening pair-wise sums are used to ensure safety from overflow
RedSum += vaddvq_u64(vpadalq_u32(
vpadalq_u32(
vpadalq_u32(
vpaddlq_u32(ZMat[0 + IterationOffset].val[0]),
ZMat[0 + IterationOffset].val[1]
),
ZMat[0 + IterationOffset].val[2]
),
ZMat[0 + IterationOffset].val[3]
));
GreenSum += vaddvq_u64(vpadalq_u32(
vpadalq_u32(
vpadalq_u32(
vpaddlq_u32(ZMat[1 + IterationOffset].val[0]),
ZMat[1 + IterationOffset].val[1]
),
ZMat[1 + IterationOffset].val[2]
),
ZMat[1 + IterationOffset].val[3]
));
BlueSum += vaddvq_u64(vpadalq_u32(
vpadalq_u32(
vpadalq_u32(
vpaddlq_u32(ZMat[2 + IterationOffset].val[0]),
ZMat[2 + IterationOffset].val[1]
),
ZMat[2 + IterationOffset].val[2]
),
ZMat[2 + IterationOffset].val[3]
));
AlphaSum += vaddvq_u64(vpadalq_u32(
vpadalq_u32(
vpadalq_u32(
vpaddlq_u32(ZMat[3 + IterationOffset].val[0]),
ZMat[3 + IterationOffset].val[1]
),
ZMat[3 + IterationOffset].val[2]
),
ZMat[3 + IterationOffset].val[3]
));
}
}
// ...Generic implementation
}
Benchmarked on my M2 Mac Mini:
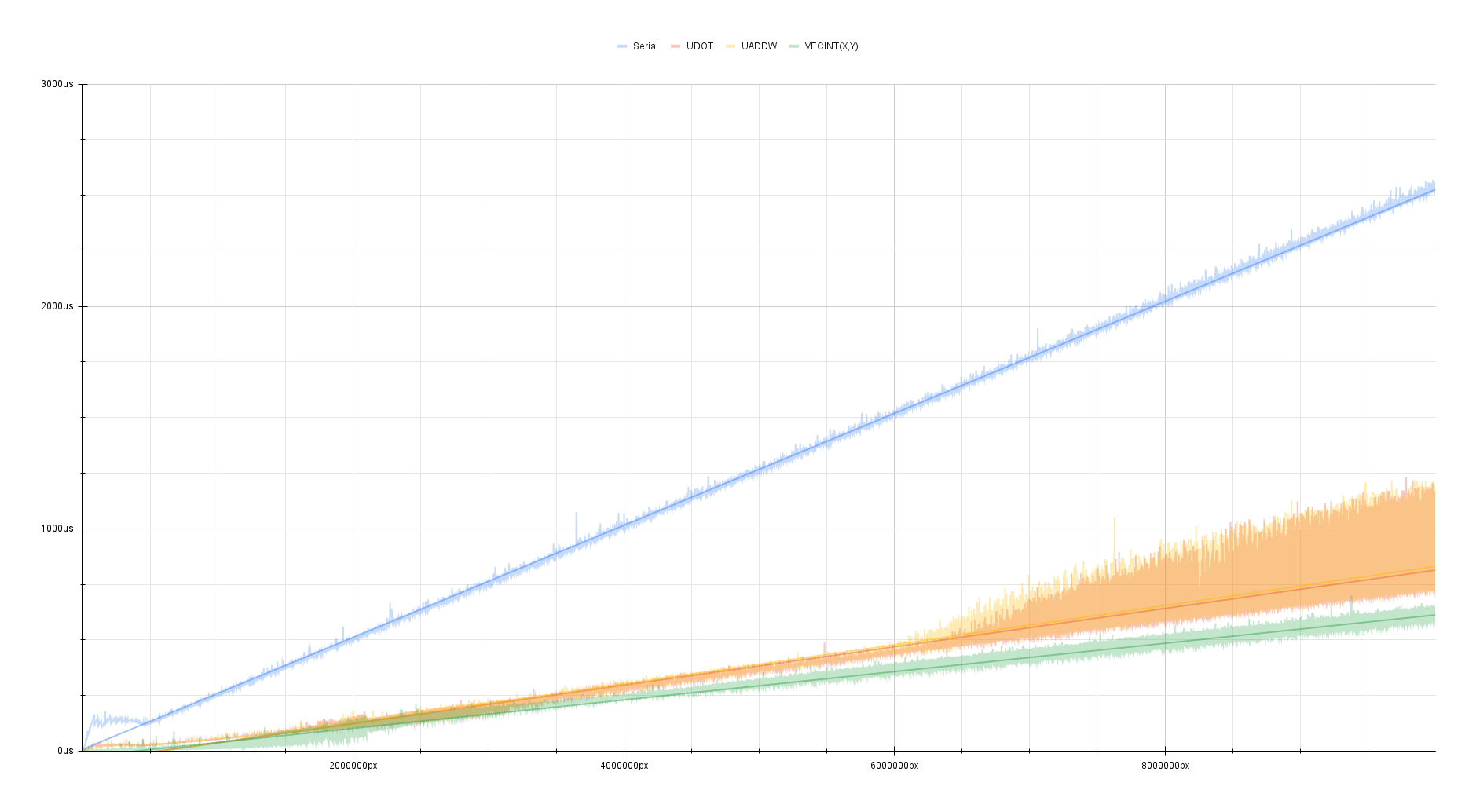
While it’s not a huge improvement over the UDOT/UADDW implementation,
it is still consistently faster than it by about
3 megapixels/ms.
| Algorithm | Speed |
|---|---|
| Generic | ~4 megapixels/ms |
UDOT/UADDW |
~13.33 megapixels/ms |
vecint(AMX) |
~16.80 megapixels/ms |
We’re processing 128 pixels at a time… Why aren’t see seeing something even close to a theoretical x128-speedup over over a serial implementation?
This could be for a lot of reasons that I didn’t care to look too deeply into
since this is just a proof-of-concept for an undocumented instruction-set that
is probably going to be deprecated.
Maybe having a slower but highly-efficient accelerator is worth sacrificing a bit of throughput? Why tie up a whole core with a highly redundant matrix/vector task when you can free-up the core for other tasks and move that workload over to an accelerator? What if the thread running this AMX code gets scheduled and pinned to the E-core implementation of AMX and not the P-Core?
Or it’s just memory-bound?
16.80 megapixels/ms translates to about 67.2 GB/s(62.58 GiB/s) of data
being processed in this tight loop which is a good chunk of the 100 GB/s
bandwidth available on the M2 considering the amount of bandwidth available for
the rest of the system.
On the M2 Pro/Max/Ultra and M3 chips, this chart would certainly look very
different!
This proof-of-concept does not even utilize the 16 “Neural Engine” cores, but there is no obvious way to utilize these for non-AI tasks.
SME
As of the newer M4 chips of 2024, Apple seems to have begun implementing the more standardized SME instruction set designed by ARM themselves. So far, only the latest iPad Pro features the M4 chip as of this writing.
Some others have already begun to analyze its characteristics:
This likely indicates an intent to remove or repurpose the AMX die-space now that there is a standard instruction-set that even developers can confidently ship into their software.
AMX instructions were never intended to be used by developers in any shipped software. These instructions are just a hidden-implementation detail of Apple’s private library-code. So ripping these instructions out of the actual hardware and making compatibility adjustments to the affected library-code would just be a bit of a quiet tragic event while clients of that library code would be none the wiser of anything happening.
Maybe my next post will be about another quirky Proof Of Concept using SVE/SME instructions now that pedestrians like me can have access to these instructions!
